KDnuggets
i ett textdokument finns det särskilda termer som representerar specifika enheter som är mer informativa och har ett unikt sammanhang. Dessa enheter är kända som namngivna enheter, som mer specifikt hänvisar till termer som representerar verkliga objekt som människor, platser, organisationer och så vidare, som ofta betecknas med egna namn. Ett naivt tillvägagångssätt kan vara att hitta dessa genom att titta på substantivfraserna i textdokument. Named entity recognition (NER), även känd som entity chunking/extraction, är en populär teknik som används i informationsutvinning för att identifiera och segmentera de namngivna enheterna och klassificera eller kategorisera dem under olika fördefinierade klasser.
SpaCy har några utmärkta funktioner för namngiven enhetsigenkänning. Låt oss försöka använda den på en av våra nyhetsartiklar.

visualisera namngivna enheter i en nyhetsartikel med spaCy
Vi kan tydligt se att de stora namngivna enheterna har identifierats med spacy. För att förstå mer detaljerat om vad varje namngiven enhet betyder kan du hänvisa till dokumentationen eller kolla in följande tabell för bekvämlighet.
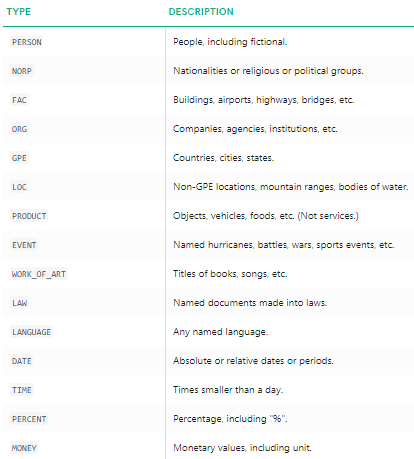
namngivna entitetstyper
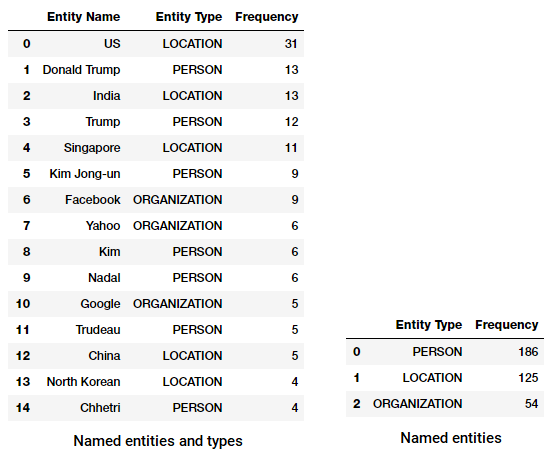
Låt oss nu ta reda på de vanligaste namngivna enheterna i vår nyhetskorpus! För detta kommer vi att bygga ut en dataram för alla namngivna enheter och deras typer med hjälp av följande kod.
Vi kan nu omvandla och aggregera denna dataram för att hitta de bästa förekommande enheterna och typerna.

toppnamn enheter och typer i våra nyheter corpus
märker du något intressant? (Tips: Kanske det förmodade toppmötet mellan Trump och Kim Jong!). Vi ser också att det har korrekt identifierat ’Messenger’ som en produkt (från Facebook).
Vi kan också gruppera efter enhetstyperna för att få en känsla av vilka typer av rättigheter som förekommer mest i vår nyhetskorpus.

topp namngivna entitetstyper i vår nyhetskorpus
Vi kan se att människor, platser och organisationer är de mest nämnda enheterna men intressant har vi också många andra enheter.
en annan trevlig ner tagger ärStanfordNERTagger tillgänglig frånnltkgränssnitt. För detta måste du ha Java installerat och sedan ladda ner Stanford NER-resurserna. Packa upp dem till en plats du väljer (jag använde E:/stanford I mitt system).
Stanfords namngivna Entity Recognizer är baserad på en implementering av linjära kedjans villkorliga slumpmässiga fält (CRF) sekvensmodeller. Tyvärr är denna modell endast utbildad på instanser av PERSON, organisation och platstyper. Följande kod kan användas som ett standardarbetsflöde som hjälper oss att extrahera de namngivna enheterna med hjälp av denna tagger och visa de toppnamnade enheterna och deras typer (extraktion skiljer sig något från spacy).
topp namngivna enheter och typer från Stanford NER på våra nyheter corpus
vi märker ganska liknande resultat men begränsade till endast tre typer av namngivna enheter. Intressant ser vi ett antal nämnda av flera personer i olika sporter.
Bio: Dipanjan Sarkar är en datavetare @ Intel, en författare, en mentor @Springboard, en författare och en sport-och sitcom missbrukare.
Original. Reposted med tillstånd.
relaterad:
- robusta Word2Vec-modeller med Gensim & tillämpa Word2Vec-funktioner för Maskininlärningsuppgifter
- Human Interpretable Machine Learning (Del 1) — behovet och betydelsen av Modelltolkning
- implementera djupa inlärningsmetoder och Funktionsteknik för textdata: Skip-gram-modellen