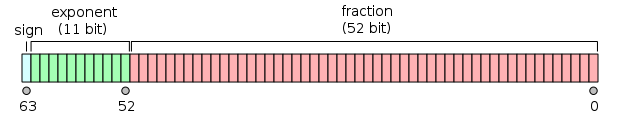
Double-precision floating-point format
double-precision Binary floating-point jest powszechnie używanym formatem na komputerach PC, ze względu na jego szerszy zakres w stosunku do pojedynczej precyzji zmiennoprzecinkowej, pomimo jego wydajności i kosztu przepustowości. Jest powszechnie znany po prostu jako podwójny. Standard IEEE 754 określa binary64 jako mający:
- bit znaku: 1 bit
- wykładnik: 11 bitów
- Significand precision: 53 bitów (52 jawnie przechowywane)
bit znaku określa znak liczby (w tym, gdy ta liczba jest zerowa, która jest podpisana).
pole wykładnika jest 11-bitową niepodpisaną liczbą całkowitą od 0 do 2047, w postaci stronniczej: wartość wykładnika 1023 reprezentuje rzeczywiste zero. Wykładniki wahają się od -1022 do +1023, ponieważ wykładniki -1023 (Wszystkie 0) i +1024 (wszystkie 1) są zarezerwowane dla liczb specjalnych.
53-bitowa dokładność znaczeniowa daje od 15 do 17 cyfr dziesiętnych dokładności (2-53 ≈ 1,11 × 10-16). Jeśli ciąg dziesiętny z co najwyżej 15 cyframi znaczącymi jest konwertowany do podwójnej precyzji IEEE 754, a następnie konwertowany z powrotem do ciągu dziesiętnego z tą samą liczbą cyfr, wynik końcowy powinien być zgodny z oryginalnym ciągiem. Jeśli Liczba o podwójnej precyzji IEEE 754 jest konwertowana na ciąg dziesiętny z co najmniej 17 cyframi znaczącymi, a następnie konwertowana z powrotem do reprezentacji o podwójnej precyzji, wynik końcowy musi być zgodny z liczbą oryginalną.
format jest zapisywany z significand o implicit integer bit o wartości 1 (z wyjątkiem danych specjalnych, patrz kodowanie wykładnika poniżej). Przy 52 bitach ułamka (F) w formacie pamięci, całkowita precyzja wynosi więc 53 bity(około 16 cyfr dziesiętnych, 53 log10 (2) ≈ 15,955). Bity są rozmieszczone w następujący sposób:
rzeczywista wartość przyjęta przez dany 64-bitowy datum o podwójnej precyzji z określonym wykładnikiem E {\displaystyle e}

I ułamek 52-bitowy to ( − 1 ) znak ( 1. b 51 b 50 . . . b 0) 2 × 2 e-1023 {\displaystyle (-1)^{\text{sign}} (1.b_{51}b_{50}…b_{0}) _ {2}\times 2^{e-1023}}

lub
( − 1 ) sign ( 1 + ∑ i = 1 52 b 52 − i 2 − i ) × 2 e − 1023 {\displaystyle (-1)^{\text{sign}}\left(1+\sum _{i=1}^{52}b_{52-i}2^{-i}\right)\times 2^{e-1023}}

między 252=4,503,599,627,370,496 i 253=9,007,199,254,740,992 liczby reprezentowane są dokładnie liczbami całkowitymi. Dla następnego przedziału, od 253 do 254, wszystko jest mnożone przez 2, więc reprezentowane liczby są parzyste, itd. Odwrotnie, dla poprzedniego zakresu od 251 do 252 odstępy wynoszą 0,5 itd.
odstęp jako ułamek liczb w zakresie od 2n do 2n+1 wynosi 2n−52.Maksymalny względny błąd zaokrąglania przy zaokrąglaniu liczby do najbliższej reprezentacyjnej (maszyna epsilon) wynosi zatem 2-53.
11-bitowa szerokość wykładnika pozwala na reprezentację liczb między 10-308 a 10308, z dokładnością 15-17 cyfr dziesiętnych. Obniżając precyzję, reprezentacja podnormalna pozwala na jeszcze mniejsze wartości do około 5 × 10-324.
Exponent encodingEdit
dwu-precyzyjny binarny wykładnik zmiennoprzecinkowy jest kodowany przy użyciu reprezentacji offset-binary, z przesunięciem zerowym wynoszącym 1023; znany również jako odchylenie wykładnicze w standardzie IEEE 754. Przykłady takich reprezentacji to:
e =00000000001200116 = 1: |
2 1 − 1023 = 2 − 1022 {\displaystyle 2^{1-1023}=2^{-1022}}
 |
(smallest exponent for normal numbers) | |
e =0111111111123ff16=1023: |
2 1023 − 1023 = 2 0 {\displaystyle 2^{1023-1023}=2^{0}}
 |
(zero offset) | |
e =10000000101240516=1029: |
2 1029 − 1023 = 2 6 {\displaystyle 2^{1029-1023}=2^{6}}
 |
||
e =1111111111027fe16=2046: |
2 2046 − 1023 = 2 1023 {\displaystyle 2^{2046-1023}=2^{1023}}
 |
(highest exponent) |
The exponents 00016 and 7ff16 have a special meaning:
-
00000000000200016is used to represent a signed zero (if F = 0) and subnormals (if F ≠ 0); i -
1111111111127ff16jest używany do reprezentowania ∞ (jeśli F = 0) i NaNs (jeśli F ≠ 0),
gdzie F jest ułamkową częścią znaczenia. Wszystkie wzorce bitowe są poprawnym kodowaniem.
z wyjątkiem powyższych WYJĄTKÓW, cała liczba podwójnej precyzji jest opisana przez:
(- 1 ) znak × 2 e − 1023 × 1. ułamek {\displaystyle (-1)^{\text{sign}} \ times 2^{e-1023} \ times 1.{\text {ułamek}}}

w przypadku podnormaliów (e = 0) liczbę podwójnej precyzji opisuje się za pomocą:
(- 1 ) znaku × 2 1 − 1023 × 0. ułamek = (- 1 ) znak × 2-1022 × 0. ułamek {\displaystyle (-1)^{\text{sign}} \ times 2^{1-1023} \ times 0.{\text {ułamek}}=(-1)^{\text {znak}} \ razy 2^{-1022} \ razy 0.{\text {ułamek}}}

EndiannessEdit
dwukierunkowe przykłady
0 01111111111 00000000000000000000000000000000000000000000000000002FF0 0000 0000 000016 ≙ +20 × 1 = 1
0 01111111111 00000000000000000000000000000000000000000000000000012ff0 0000 0000 000116 ≙ +20 × (1 + 2-52) ≈ 1.0000000000000002, the smallest number > 1
0 01111111111 00000000000000000000000000000000000000000000000000102 ≙ 3FF0 0000 0000 000216 ≙ +20 × (1 + 2−51) ≈ 1.0000000000000004
0 10000000000 00000000000000000000000000000000000000000000000000002 ≙ 4000 0000 0000 000016 ≙ +21 × 1 = 2
1 10000000000 00000000000000000000000000000000000000000000000000002 ≙ C000 0000 0000 000016 ≙ −21 × 1 = −2
0 10000000000 10000000000000000000000000000000000000000000000000002 ≙ 4008 0000 0000 000016 ≙ +21 × 1.12 = 112 = 3
0 10000000001 00000000000000000000000000000000000000000000000000002 ≙ 4010 0000 0000 000016 ≙ +22 × 1 = 1002 = 4
0 10000000001 01000000000000000000000000000000000000000000000000002 ≙ 4014 0000 0000 000016 ≙ +22 × 1.012 = 1012 = 5
0 10000000001 10000000000000000000000000000000000000000000000000002 ≙ 4018 0000 0000 000016 ≙ +22 × 1.12 = 1102 = 6
0 10000000011 01110000000000000000000000000000000000000000000000002 ≙ 4037 0000 0000 000016 ≙ +24 × 1.01112 = 101112 = 23
0 01111111000 10000000000000000000000000000000000000000000000000002 ≙ 3F88 0000 0000 000016 ≙ +2−7 × 1.12 = 0.000000112 = 0.01171875 (3/256)
0 00000000000 00000000000000000000000000000000000000000000000000012 ≙ 0000 0000 0000 000116 ≙ +2−1022 × 2−52 = 2−1074
≈ 4.9406564584124654 × 10−324 (Min. subnormal positive double)
0 00000000000 11111111111111111111111111111111111111111111111111112 ≙ 000F FFFF FFFF FFFF16 ≙ +2−1022 × (1 − 2−52)
≈ 2.2250738585072009 × 10−308 (Max. subnormal double)
0 00000000001 00000000000000000000000000000000000000000000000000002 ≙ 0010 0000 0000 000016 ≙ +2−1022 × 1
≈ 2.2250738585072014 × 10−308 (Min. normal positive double)
0 11111111110 11111111111111111111111111111111111111111111111111112 ≙ 7FEF FFFF FFFF FFFF16 ≙ +21023 × (1 + (1 − 2−52))
≈ 1.7976931348623157 × 10308 (Max. Double)
0 00000000000 00000000000000000000000000000000000000000000000000002 ≙ 0000 0000 0000 000016 ≙ +0
1 00000000000 00000000000000000000000000000000000000000000000000002 ≙ 8000 0000 0000 000016 ≙ −0
0 11111111111 00000000000000000000000000000000000000000000000000002 ≙ 7FF0 0000 0000 000016 ≙ +∞ (positive infinity)
1 11111111111 00000000000000000000000000000000000000000000000000002 ≙ FFF0 0000 0000 000016 ≙ −∞ (negative infinity)
0 11111111111 00000000000000000000000000000000000000000000000000012 ≙ 7FF0 0000 0000 000116 ≙ NaN (sNaN on most processors, such as x86 and ARM)
0 11111111111 10000000000000000000000000000000000000000000000000012 ≙ 7FF8 0000 0000 000116 ≙ NaN (qNaN on most processors, such as x86 and ARM)
0 11111111111 11111111111111111111111111111111111111111111111111112FFF FFFF ffff ffff16 ≙ Nan (alternatywne kodowanie NaN)
0 01111111101 01010101010101010101010101010101010101010101010101012 = 3FD5 5555 5555 555516 ≙ +2-2 × (1 + 2-2 + 2-4 + … + 2-52) ≈ 1/3
0 10000000000 10010010000111111011010101000100010000101101000110002 = 4009 21FB 5444 2d1816 ≈ pi
kodowanie qNaN i sNaN nie jest w pełni określone w IEEE 754 i zależy od procesora. Większość procesorów, takich jak rodzina x86 i rodzina ARM, używa najbardziej znaczącego bitu pola significand, aby wskazać ciche NaN; jest to zalecane przez IEEE 754. Procesory PA-RISC używają bitu do sygnalizacji Nan.
domyślnie 1/3 zaokrągla się w dół, zamiast w górę jak pojedyncza precyzja, ze względu na nieparzystą liczbę bitów w znaczniku.
bardziej szczegółowo:
Given the hexadecimal representation 3FD5 5555 5555 555516, Sign = 0 Exponent = 3FD16 = 1021 Exponent Bias = 1023 (constant value; see above) Fraction = 5 5555 5555 555516 Value = 2(Exponent − Exponent Bias) × 1.Fraction – Note that Fraction must not be converted to decimal here = 2−2 × (15 5555 5555 555516 × 2−52) = 2−54 × 15 5555 5555 555516 = 0.333333333333333314829616256247390992939472198486328125 ≈ 1/3
szybkość wykonywania z podwójną precyzją arithmeticEdit
przy użyciu podwójnych precyzyjnych zmiennych zmiennoprzecinkowych i funkcji matematycznych (np. sin, cos, atan2, log, exp i sqrt) są wolniejsze niż praca z ich pojedynczymi precyzyjnymi odpowiednikami. Jednym z obszarów obliczeniowych, w którym jest to szczególny problem, jest równoległy kod działający na GPU. Na przykład, gdy korzystasz z platformy CUDA firmy NVIDIA, obliczenia z podwójną precyzją trwają, w zależności od sprzętu, około 2 do 32 razy dłużej niż obliczenia wykonywane przy użyciu pojedynczej precyzji.
ograniczenia precyzji wartości liczbowychedit
- liczby całkowite od -253 do 253 (-9007199254740992 do 9007199254740992) mogą być dokładnie reprezentowane
- liczby całkowite od 253 do 254 = 18014398509481984 okrągłe do wielokrotności 2 (liczba parzysta)
- liczby całkowite od 254 do 255 = 36028797018963968 do wielokrotności 4
/li>