データマイニングチュートリアル:|プロセス/テクニックと例とは何ですか
データマイニングとは何ですか?
データマイニングは、巨大なデータセットから潜在的に有用なパターンを見つけるプロセスです。 これは、機械学習、統計、およびAIを使用して情報を抽出し、将来のイベントの確率を評価する学際的なスキルです。 データマイニングから得られた洞察は、マーケティング、詐欺の検出、科学的発見などに使用されます。
データマイニングは、データ間の隠された、疑われていない、以前は未知でありながら有効な関係を発見することです。 データマイニングは、データにおける知識発見(KDD)、知識抽出、データ/パターン分析、情報収集などとも呼ばれます。 このデータマイニングチュートリアルでは、データマイニングの基礎を次のように学びます。
- データマイニングとは何ですか?
- データの種類
- データマイニング実装プロセス
- ビジネス理解:
- データ理解:
- データ準備:
- データ変換:
- モデリング:
- データマイニング技術
- データマイニングの実装の課題:
- データマイニング例:
- データマイニングツール
- データマイニングの利点:
- データマイニングの欠点
- データマイニングアプリケーション
データの種類
データマイニングは、次のタイプのデータに対して実行できます
- リレーショナルデータベース
- データウェアハウス
- 高度なDBおよび情報リポジトリ
- オブジェクト指向およびオブジェクトリレーショナルデータベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- トランザクションおよび空間データベース
- データベース
- 異種およびレガシーデータベース
- マルチメディアおよびストリーミングデータベース
- テキストデータベース
- テキストマイニングとウェブマイニング
データマイニングの実装 プロセス

データマイニング実装プロセスを詳細に研究してみましょう
ビジネス理解:
このフェーズでは、ビジネスとデータマイニング
- まず、ビジネスとクライアントの目的を理解する必要があります。 クライアントが何を望んでいるかを定義する必要があります(何度も自分自身を知らなくても)
- 現在のデータマイニングシナリオの在庫を取ります。 あなたの評価にリソース、仮定、制約、およびその他の重要な要因の要因。
- ビジネス目標と現在のシナリオを使用して、データマイニングの目標を定義します。
- 優れたデータマイニングプランは非常に詳細であり、ビジネスとデータマイニングの両方の目標を達成するために開発する必要があります。
データの理解:
このフェーズでは、データの健全性チェックが実行され、データマイニングの目標に適しているかどうかが確認されます。
- まず、組織で利用可能な複数のデータソースからデータが収集されます。
- これらのデータソースには、複数のデータベース、フラットファイラー、またはデータキューブが含まれます。 データ統合プロセス中に発生する可能性のあるオブジェクトの一致やスキーマの統合などの問題があります。 さまざまなソースからのデータが簡単に一致する可能性は低いため、非常に複雑でトリッキーなプロセスです。 たとえば、表Aにはcust_noという名前のエンティティが含まれていますが、別の表Bにはcust-idという名前のエンティティが含まれています。
- したがって、これらの指定されたオブジェクトの両方が同じ値を参照するかどうかを確認することは非常に困難です。 ここでは、データ統合プロセスのエラーを減らすためにメタデータを使用する必要があります。
- 次に、取得したデータのプロパティを検索するステップです。 データを探索するには、クエリ、レポート、および可視化ツールを使用して、データマイニングの質問(ビジネスフェーズで決定)に答えることをお勧めします。
- クエリの結果に基づいて、データ品質を確認する必要があります。 取得する必要がある場合は、データが欠落しています。
データ準備:
このフェーズでは、データは生産準備ができています。
データ準備プロセスは、プロジェクトの時間の約90%を消費します。
異なるソースからのデータは、選択、クリーンアップ、変換、フォーマット、匿名化、および(必要に応じて)構築する必要があります。
データクリーニングは、ノイズの多いデータを平滑化し、欠損値を入力することによってデータを”クリーニング”するプロセスです。
たとえば、顧客の人口統計プロファイルでは、年齢データが欠落しています。 データは不完全であり、記入する必要があります。 場合によっては、データの外れ値が存在する可能性があります。 たとえば、ageの値は300です。 データに矛盾がある可能性があります。 たとえば、顧客の名前はテーブルごとに異なります。
データ変換操作は、データマイニングに役立つようにデータを変更します。 次の変換を適用することができます
データ変換:
データ変換操作は、マイニングプロセスの成功に貢献します。
平滑化: これは、データからノイズを除去するのに役立ちます。 集計:集計操作または集計操作がデータに適用されます。
集計:集計操作または集計操作がデータに適用されます。 すなわち、毎週の売上データは、毎月および毎年の合計を計算するために集計されます。
一般化:このステップでは、概念階層の助けを借りて、低レベルのデータがより高いレベルの概念に置き換えられます。 たとえば、都市は郡に置き換えられます。
正規化:属性データがスケールアップされたときに実行される正規化oスケールダウンします。 例:データは、正規化後に-2.0から2.0の範囲に収まる必要があります。
属性の構築: これらの属性は、データマイニングに役立つ特定の属性セットが構築され、含まれています。 このプロセスの結果は、モデリングに使用できる最終的なデータセットです。
このプロセスの結果は、モデリングに使用できる最終的なデータセッ
モデリング
このフェーズでは、数学的モデルがデータパターンを決定するために使用されます。
- ビジネス目標に基づいて、準備されたデータセットに適したモデリング技術を選択する必要があります。
- モデルの品質と有効性をテストするシナリオを作成します。
- 準備されたデータセットでモデルを実行します。
- 結果は、モデルがデータマイニングの目標を満たすことができることを確認するために、すべての利害関係者によって評価されるべきです。
評価:
このフェーズでは、識別されたパターンがビジネス目標に対して評価されます。
- データマイニングモデルによって生成された結果は、ビジネス目標に対して評価する必要があります。
- ビジネスの理解を得ることは反復的なプロセスです。 実際には、理解しながら、データマイニングのために新しいビジネス要件が提起される可能性があります。
- 展開フェーズでモデルを移動するには、goまたはno-goの決定が行われます。
Deployment:
deploymentフェーズでは、データマイニングの検出を日常のビジネスオペレーションに出荷します。
- データマイニングプロセス中に発見された知識や情報は、非技術的な利害関係者にとって理解しやすくする必要があります。
- データマイニング検出の出荷、保守、および監視のための詳細な展開計画が作成されます。
- 最終的なプロジェクトレポートは、プロジェクト中に学んだ教訓と重要な経験を使用して作成されます。 これは、組織のビジネスポリシーを改善するのに役立ちます。
データマイニング技術
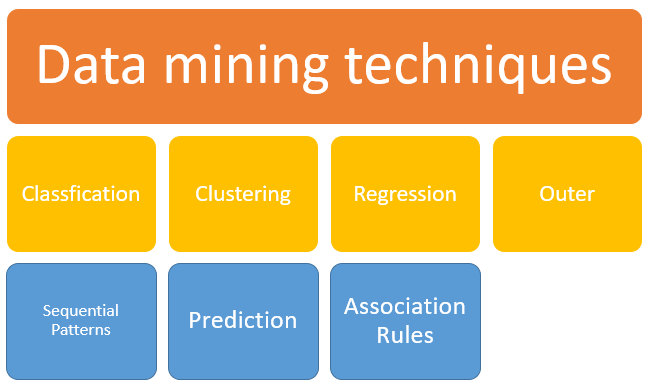
1.分類:
この分析は、データおよびメタデータに関する重要かつ関連性の高い情報を取得するために使用されます。 このデータマイニングメソッドは、異なるクラスのデータを分類するのに役立ちます。
2. クラスタリング:
クラスタリング分析は、互いに似たデータを識別するためのデータマイニング技術です。 このプロセスは、データ間の相違点と類似点を理解するのに役立ちます。
3. 回帰分析は、変数間の関係を識別して分析するデータマイニング方法です。 これは、他の変数が存在する場合、特定の変数の尤度を識別するために使用されます。
4. 関連ルール:
このデータマイニング手法は、2つ以上のアイテム間の関連付けを見つけるのに役立ちます。 これは、データセット内の非表示のパターンを検出します。
5. 外の検出:
このタイプのデータマイニング手法は、予想されるパターンまたは予想される動作に一致しないデータセット内のデータ項目の観察を指します。 この技術は、侵入、検出、詐欺または障害検出などのさまざまなドメインで使用できます。 外部検出は、外れ値解析または外れ値マイニングとも呼ばれます。
6. 順次パターン:
このデータマイニング技術は、特定の期間のトランザクションデータの同様のパターンや傾向を発見または識別するのに役立ちます。
7. 予測:
予測は、傾向、順次パターン、クラスタリング、分類などのデータマイニングの他の技術の組み合わせを使用しています。 これは、将来のイベントを予測するための適切な順序で過去のイベントやインスタンスを分析します。
データマイニングの実装の課題:
- 熟練した専門家は、データマイニングクエリを策定するために必要とされています。
- Overfitting:サイズのトレーニングデータベースが小さいため、モデルは将来の状態に合わない場合があります。
- データマイニングには大規模なデータベースが必要で、管理が困難な場合があります
- ビジネス慣行は、発見された情報を使用するかどうかを決定
- データセットが多様でない場合、データマイニングの結果は正確ではない可能性があります。
- 異種データベースやグローバル情報システムから必要な統合情報は複雑になる可能性があります
データマイニングの例:
このデータマイニングコースでは、例を使ってデータマイニングについて学びましょう。
例1:
通信サービスのマーケティングヘッドを検討してください長距離サービスの収益を増加させたい人が提供しています。 彼の販売および売込みの顧客の側面図を描くことの高いROIのために重要である。 彼は、年齢、性別、収入、信用履歴などの顧客情報の膨大なデータプールを持っています。 しかし、手動分析で長距離通話を好む人々の特性を判断することは不可能です。 データマイニング技術を使用して、彼は高い長距離通話ユーザーとその特性との間のパターンを明らかにするかもしれません。
たとえば、彼は彼の最高の顧客は、年間以上$80,000作る45と54の年齢の間に結婚した女性であることを学ぶかもしれません。 マーケティング活動はそのような人口統計学に目標とすることができます。
例2:
銀行は、クレジットカードの操作から収入を増やすための新しい方法を検索したいと考えています。 彼らは、料金が半分になった場合、使用量が倍増するかどうかを確認したいと考えています。
銀行は、平均的なクレジットカードの残高、支払い金額、与信限度額の使用、およびその他の重要なパラメータのレコードの複数の年を持っています。 彼らは、提案された新しいビジネスポリシーの影響をチェックするためのモデルを作成します。 データの結果は、ターゲット顧客ベースのための半分に手数料を削減することはrevenues10百万収入を増加させることができることを示しています。
データマイニングツール
以下は、業界で広く使用されている2つの人気のあるデータマイニングツールです
R言語:
R言語は、統計コンピュー Rには、さまざまな統計的、古典的な統計的検定、時系列分析、分類、およびグラフィカルな手法があります。 それは有効なデータ渡すことおよび貯蔵設備を提供します。 ODMはOracle Advanced Analyticsデータベースのモジュールであるため、Oracle Data Miningは一般に知られています。 このデータマイニングツールを使用すると、データアナリストは詳細な洞察を生成し、予測を行うことができます。 それは顧客の行動を予測し、顧客のプロフィールを開発し、交差販売の機会を識別するのを助ける。
詳細はこちら
データマイニングの利点:
- データマイニング技術は、企業が知識ベースの情報を取得するのに役立ちます。
- データマイニングは、組織が運用と生産で収益性の高い調整を行うのに役立ちます。
- データマイニングは、他の統計データアプリケーションと比較して費用対効果が高く効率的なソリューションです。
- データマイニングは意思決定プロセスに役立ちます。
- は、傾向や行動の自動予測だけでなく、隠されたパターンの自動検出を容易にします。
- これは、新しいシステムだけでなく、既存のプラットフォームで実装することができます
- それは、ユーザーがより少ない時間で膨大な量のデータを分析
データマイニングの短所
- 企業が顧客の有用な情報を他の企業にお金のために販売する可能性があります。 例えば、アメリカン-エキスプレスは他の会社に顧客のクレジットカードの購入を販売した。
- 多くのデータマイニング分析ソフトウェアは、操作が困難であり、上で動作するように事前の訓練が必要です。
- 異なるデータマイニングツールは、設計に採用されているアルゴリズムが異なるため、異なる方法で動作します。 したがって、正しいデータマイニングツールの選択は非常に困難な作業です。
- データマイニング技術は正確ではないため、特定の条件で深刻な結果を引き起こす可能性があります。
データマイニングアプリケーション
| アプリケーション | 使用法 |
|---|---|
| 通信 | データマイニング技術は、非常にターゲットと関連性の高いキャンペーンを提供するために、顧客の行動を予測するために通信部門で使用されています。 |
| 保険 | データマイニングは、保険会社が収益性の高い製品の価格を設定し、新規または既存の顧客に新しいオファーを促進するのに役立ちます。 |
| 教育 | データマイニングは、教育者が学生のデータにアクセスし、達成レベルを予測し、特別な注意を必要とする学生や学生のグループを見つ 例えば、数学の科目に弱い学生。 |
| 製造 | データマイニングメーカーの助けを借りて、生産資産の消耗を予測することができます。 彼らはダウンタイムを最小にするためにそれらを減らすのを助ける維持を予想してもいい。 |
| 銀行 | データマイニングは、市場リスクのビューを取得し、規制遵守を管理するために金融部門を支援します。 これは、銀行がクレジットカード、ローンなどを発行するかどうかを決定する可能性のある滞納者を識別するのに役立ちます。 |
| 小売 | データマイニング技術は、小売モールや食料品店が最も丁寧な位置に最も販売可能なアイテムを特定し、手配するのに役立ちます。 それは店の所有者が彼らの支出を増やすために顧客を奨励するオファーを思い付くのに役立ちます。 |
| サービスプロバイダー | 携帯電話やユーティリティ業界のようなサービスプロバイダーは、顧客が自分の会社を離れる理由を予測するためにデータ 彼らは、請求の詳細、顧客サービスの相互作用、各顧客に確率スコアを割り当てるために会社に行われた苦情を分析し、インセンティブを提供しています。 |
| 電子商取引 | 電子商取引ウェブサイトは、データマイニングを使用して、ウェブサイトを通じてクロスセルとアップセルを提供します。 最も有名な名前の一つは、彼らのeコマースストアに多くの顧客を得るためにデータマイニング技術を使用してAmazon、です。 |
| スーパーマーケット | データマイニングにより、スーパーマーケットの開発ルールは、買い物客が期待する可能性が高いかどうかを予測することができます。 彼らの購買パターンを評価することによって、彼らは最も可能性の高い妊娠している女性の顧客を見つけることができます。 それらは赤ん坊の粉、赤ん坊の店、おむつのようなプロダクトを等目標とし始めてもいいです。 |
| 犯罪捜査 | データマイニングは、犯罪捜査機関が警察の労働力を展開するのに役立ちます(犯罪が発生する可能性が最も高い場所といつ)、国境の交差点などで検索する人。 |
| バイオインフォマティクス | データマイニングは、生物学と医学で収集された大規模なデータセットから生物学的データを採掘するのに役立ちます。 |
概要:
- データマイニングの定義:データマイニングは、過去を説明し、データ分析を介して未来を予測することに関するものです。
- データマイニングは、膨大なデータセットから情報を抽出するのに役立ちます。 これは、データから知識を採掘する手順です。
- データマイニングプロセスは、ビジネスの理解、データ理解、データ準備、モデリング、進化、展開が含まれています。
- 重要なデータマイニング技術は、分類、クラスタリング、回帰、関連ルール、外部検出、順次パターン、および予測です
- R-languageとOracle Data miningは、著名なデータマイニングツール
- データマイニング技術は、企業が知識ベースの情報を取得するのに役立ちます。
- データマイニングの主な欠点は、多くの分析ソフトウェアが操作が困難であり、作業するために事前のトレーニングが必要であることです。
- データマイニングは、通信、保険、教育、製造、銀行、小売、サービスプロバイダ、eコマース、スーパーマーケットのバイオインフォマティクスなどの多様な産業で使用