Data Mining Tutorial: Hvad er | proces / teknikker & eksempler
Hvad er Data Mining?
Data Mining er en proces med at finde potentielt nyttige mønstre fra store datasæt. Det er en tværfaglig færdighed, der bruger maskinindlæring, statistik og AI til at udtrække information for at evaluere fremtidige begivenheders Sandsynlighed. Den indsigt, der stammer fra data Mining, bruges til markedsføring, afsløring af svig, videnskabelig opdagelse osv.
Data Mining handler om at opdage skjulte, ikke-mistænkte og tidligere ukendte, men gyldige forhold mellem dataene. Data mining kaldes også Videnopdagelse i Data (KDD), vidensudvinding, data/mønsteranalyse, informationshøstning osv.
i denne Data Mining tutorial, vil du lære de grundlæggende elementer i Data Mining ligesom-
- hvad er Data Mining?
- typer af Data
- Data Mining implementeringsproces
- forretningsforståelse:
- dataforståelse:
- data forberedelse:
- data transformation:
- modellering:
- data mining teknikker
- udfordringer ved implementering af Data Mine:
- Data Mining eksempler:
- data mining værktøjer
- fordele ved data mining:
- ulemper ved Data Mining
- data mining Applications
datatyper
data mining kan udføres på følgende typer data
- relationsdatabaser
- datalagre
- avanceret DB og informationsarkiver
- objektorienterede og objekt-relationelle databaser
- transaktions-og rumlige databaser
- heterogene og ældre databaser
- multimedie-og streamingdatabase
- tekstdatabaser
- tekstminedrift og internetminedrift
implementering af data mining Proces

lad os studere implementeringsprocessen for data mining i detaljer
forretningsforståelse:
i denne fase etableres forretnings-og data-Mining-mål.
- først skal du forstå forretnings-og klientmål. Du skal definere, hvad din klient ønsker (som mange gange selv de ikke kender sig selv)
- gør status over det aktuelle data mining scenario. Faktor i ressourcer, antagelse, begrænsninger og andre væsentlige faktorer i din vurdering.
- brug forretningsmål og nuværende scenario til at definere dine data mining-mål.
- en god data mining plan er meget detaljeret og bør udvikles for at opnå både forretnings-og data mining mål.
dataforståelse:
i denne fase udføres sanity check på data for at kontrollere, om det passer til data mining-målene.
- først indsamles data fra flere datakilder, der er tilgængelige i organisationen.
- disse datakilder kan omfatte flere databaser, flade filer eller datakuber. Der er problemer som objekt matching og skema integration, som kan opstå under Dataintegrationsprocessen. Det er en ret kompleks og vanskelig proces, da data fra forskellige kilder sandsynligvis ikke matcher let. For eksempel indeholder tabel A en enhed med navnet cust_no, mens en anden tabel B indeholder en enhed med navnet cust-id.
- derfor er det ret vanskeligt at sikre, at begge disse givne objekter henviser til samme værdi eller ej. Her skal Metadata bruges til at reducere fejl i dataintegrationsprocessen.
- dernæst er trinnet at søge efter egenskaber for erhvervede data. En god måde at udforske dataene på er at besvare data mining-spørgsmålene (besluttet i forretningsfasen) ved hjælp af forespørgsels -, rapporterings-og visualiseringsværktøjerne.
- baseret på resultaterne af forespørgslen skal datakvaliteten fastslås. Manglende data, hvis nogen skulle erhverves.
dataforberedelse:
i denne fase gøres data produktionsklar.
dataforberedelsesprocessen bruger omkring 90% af projektets tid.
dataene fra forskellige kilder skal vælges, rengøres, transformeres, formateres, anonymiseres og konstrueres (hvis nødvendigt).
datarensning er en proces til at “rense” dataene ved at udjævne støjende data og udfylde manglende værdier.
for eksempel mangler aldersdata for en kundedemografiprofil. Oplysningerne er ufuldstændige og skal udfyldes. I nogle tilfælde kan der være data outliers. For eksempel har alder en værdi 300. Data kan være inkonsekvente. For eksempel er kundens navn forskelligt i forskellige tabeller.
Datatransformationsoperationer ændrer dataene for at gøre dem nyttige i data mining. Efter transformation kan anvendes
datatransformation:
Datatransformationsoperationer vil bidrage til succesen med mineprocessen.
udjævning: Det hjælper med at fjerne støj fra dataene.
aggregering: Opsummerings-eller aggregeringsoperationer anvendes på dataene. Dvs. de ugentlige salgsdata aggregeres for at beregne den månedlige og årlige total.
generalisering: i dette trin erstattes data på lavt niveau med koncepter på højere niveau ved hjælp af koncepthierarkier. For eksempel erstattes byen af amtet.
normalisering: normalisering udføres, når attributdataene skaleres op o skaleres ned. Eksempel: Data skal falde i området -2,0 til 2,0 efter normalisering.
attribut konstruktion: disse attributter er konstrueret og inkluderet det givne sæt attributter, der er nyttige til data mining.
resultatet af denne proces er et endeligt datasæt, der kan bruges i modellering.
modellering
i denne fase bruges matematiske modeller til at bestemme datamønstre.
- baseret på forretningsmålene skal der vælges passende modelleringsteknikker til det forberedte datasæt.
- Opret et scenario for at teste kontrollere kvaliteten og gyldigheden af modellen.
- Kør modellen på det forberedte datasæt.
- resultater bør vurderes af alle interessenter for at sikre, at modellen kan opfylde data mining mål.
evaluering:
i denne fase evalueres identificerede mønstre i forhold til forretningsmålene.
- resultater genereret af data mining-modellen skal evalueres i forhold til forretningsmålene.
- at få forretningsforståelse er en iterativ proces. Faktisk, mens forståelse, kan nye forretningskrav hæves på grund af data mining.
- der træffes en go-eller no-go-beslutning om at flytte modellen i implementeringsfasen.
implementering:
i implementeringsfasen sender du dine data mining-opdagelser til hverdagens forretningsdrift.
- den viden eller information, der opdages under data mining-processen, skal gøres let at forstå for ikke-tekniske interessenter.
- Der oprettes en detaljeret implementeringsplan for forsendelse, vedligeholdelse og overvågning af data mining-opdagelser.
- en endelig projektrapport oprettes med erfaringer og nøgleoplevelser under projektet. Dette hjælper med at forbedre organisationens forretningspolitik.
data Mining teknikker
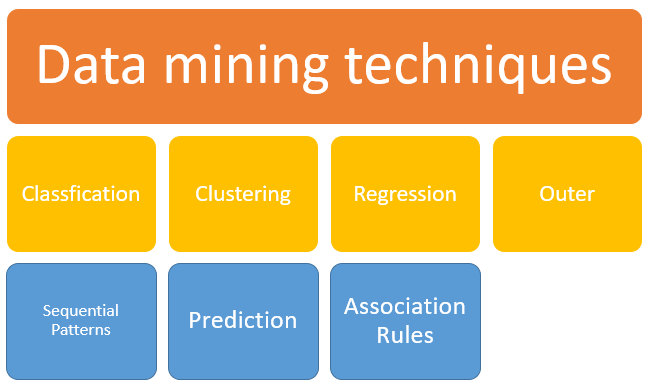
1.Klassificering:
denne analyse bruges til at hente vigtige og relevante oplysninger om data og metadata. Denne data mining metode hjælper med at klassificere data i forskellige klasser.
2. Clustering:
Clustering analyse er en data mining teknik til at identificere data, der er som hinanden. Denne proces hjælper med at forstå forskellene og lighederne mellem dataene.
3. Regression:
regressionsanalyse er data mining-metoden til at identificere og analysere forholdet mellem variabler. Det bruges til at identificere sandsynligheden for en bestemt variabel i betragtning af tilstedeværelsen af andre variabler.
4. Associeringsregler:
denne data mining-teknik hjælper med at finde sammenhængen mellem to eller flere elementer. Det opdager et skjult mønster i datasættet.
5. Ydre detektion:
denne type data mining teknik refererer til observation af dataelementer i datasættet, som ikke matcher et forventet mønster eller forventet adfærd. Denne teknik kan bruges i en række domæner, såsom indtrængen, detektion, svig eller fejldetektion osv. Ydre detektion kaldes også Outlier analyse eller Outlier minedrift.
6. Sekventielle mønstre:
denne data mining-teknik hjælper med at opdage eller identificere lignende mønstre eller tendenser i transaktionsdata i en bestemt periode.
7. Forudsigelse:
forudsigelse har brugt en kombination af de andre teknikker til data mining som tendenser, sekventielle mønstre, klyngedannelse, klassificering osv. Den analyserer tidligere begivenheder eller forekomster i en rigtig rækkefølge for at forudsige en fremtidig begivenhed.
udfordringer ved implementering af Datamine:
- dygtige eksperter er nødvendige for at formulere data mining-forespørgsler.
- Overfitting: på grund af lille størrelse uddannelse database, kan en model ikke passer fremtidige stater.
- Data Mining har brug for store databaser, som undertiden er vanskelige at administrere
- forretningspraksis skal muligvis ændres for at bestemme at bruge de afdækkede oplysninger.
- hvis datasættet ikke er forskelligt, er data mining-resultaterne muligvis ikke korrekte.
- Integrationsoplysninger, der er nødvendige fra heterogene databaser og globale informationssystemer, kan være komplekse
Data Mining eksempler:
nu i dette Data Mining kursus, lad os lære om Data mining med eksempler:
eksempel 1:
overvej en marketingchef for telecom-service, der ønsker at øge indtægterne fra langdistancetjenester. For høj ROI på hans Salgs-og marketingindsats er kundeprofilering vigtig. Han har en enorm datapool af kundeoplysninger som alder, køn, indkomst, kredit historie, etc. Men det er umuligt at bestemme karakteristika for mennesker, der foretrækker langdistanceopkald med manuel analyse. Ved hjælp af data mining teknikker, kan han afdække mønstre mellem høje langdistance opkald brugere og deres egenskaber.
for eksempel kan han lære at hans bedste kunder er gift kvinder mellem 45 og 54 år, der tjener mere end $80.000 om året. Marketingindsats kan målrettes mod sådan demografisk.
eksempel 2:
en bank ønsker at søge nye måder at øge indtægterne fra sine kreditkortoperationer. De ønsker at kontrollere, om brugen ville fordoble, hvis gebyrerne blev halveret.
Bank har flere års rekord på gennemsnitlige kreditkortsaldi, betalingsbeløb, brug af kreditgrænse og andre nøgleparametre. De skaber en model for at kontrollere virkningen af den foreslåede nye forretningspolitik. Dataresultaterne viser, at nedskæring af gebyrer i halvdelen for en målrettet kundebase kan øge indtægterne med $10 millioner.
data mining Tools
Følgende er 2 populære Data mining værktøjer meget udbredt i industrien
r-sprog:
r sprog er et open source værktøj til statistisk computing og grafik. R har en bred vifte af statistiske, klassiske statistiske tests, tidsserieanalyse, klassificering og grafiske teknikker. Det tilbyder effektiv data aflevering og lagerfacilitet.
Lær mere her
Oracle Data Mining:
Oracle Data Mining populært kendt som ODM er et modul i Oracle Advanced Analytics Database. Dette Data mining værktøj giver data analytikere til at generere detaljerede indsigter og gør forudsigelser. Det hjælper med at forudsige kundeadfærd, Udvikler kundeprofiler, identificerer krydssalgsmuligheder.
Lær mere her
fordele ved data mining:
- Data Mining teknik hjælper virksomheder med at få videnbaseret information.
- Data mining hjælper organisationer med at foretage de rentable justeringer i drift og produktion.
- data mining er en omkostningseffektiv og effektiv løsning i forhold til andre statistiske data applikationer.
- Data mining hjælper med beslutningsprocessen.
- Letter automatiseret forudsigelse af tendenser og adfærd samt automatiseret opdagelse af skjulte mønstre.
- det kan implementeres i nye systemer såvel som eksisterende platforme
- det er den hurtige proces, der gør det nemt for brugerne at analysere enorme mængder data på kortere tid.
ulemper ved data mining
- Der er chancer for, at virksomheder kan sælge nyttige oplysninger om deres kunder til andre virksomheder for penge. For eksempel har Amerikanske Ekspres solgt kreditkort køb af deres kunder til de andre selskaber.
- mange data mining-analyseprogrammer er vanskelige at betjene og kræver forudgående træning for at arbejde på.
- forskellige data mining-værktøjer fungerer på forskellige måder på grund af forskellige algoritmer, der anvendes i deres design. Derfor er udvælgelsen af korrekt data mining værktøj er en meget vanskelig opgave.
- data mining-teknikkerne er ikke korrekte, og det kan derfor medføre alvorlige konsekvenser under visse forhold.
data mining Applications
| applikationer | anvendelse |
|---|---|
| kommunikation | Data mining teknikker bruges i kommunikationssektoren til at forudsige kundeadfærd for at tilbyde meget målrettede og relevante kampagner. |
| forsikring | Data mining hjælper forsikringsselskaber med at prissætte deres produkter rentable og fremme nye tilbud til deres nye eller eksisterende kunder. |
| uddannelse | Data mining gavner undervisere til at få adgang til studerendes data, forudsige præstationsniveauer og finde studerende eller grupper af studerende, der har brug for ekstra opmærksomhed. For eksempel studerende, der er svage i matematikfaget. |
| fremstilling | ved hjælp af Data mining producenter kan forudsige slitage af produktionsaktiver. De kan forudse vedligeholdelse, som hjælper dem med at reducere dem for at minimere nedetid. |
| Banking | Data mining hjælper finanssektoren med at få et overblik over markedsrisici og styre overholdelse af lovgivningen. Det hjælper bankerne med at identificere sandsynlige misligholdere til at beslutte, om de skal udstede kreditkort, lån osv. |
| Retail | data mining teknikker hjælpe detail indkøbscentre og købmandsforretninger identificere og arrangere mest salgbare elementer i de mest opmærksomme positioner. Det hjælper butiksejere med at komme med det tilbud, der tilskynder kunderne til at øge deres udgifter. |
| tjenesteudbydere | tjenesteudbydere som mobiltelefon-og forsyningsindustrier bruger Data Mining til at forudsige årsagerne, når en kunde forlader deres virksomhed. De analyserer faktureringsoplysninger, kundeserviceinteraktioner, klager til virksomheden for at tildele hver kunde en sandsynlighedsscore og tilbyder incitamenter. |
| E-handel | E-handel hjemmesider bruger Data Mining til at tilbyde cross-sælger og op-sælger gennem deres hjemmesider. En af de mest berømte navne er |
| supermarkeder | Data Mining tillader supermarkedets udviklings regler at forudsige, om deres kunder sandsynligvis ville forvente. Ved at evaluere deres købsmønster, de kunne finde kvindelige kunder, der sandsynligvis er gravide. De kan begynde at målrette produkter som babypulver, babybutik, bleer og så videre. |
| Kriminalitetsundersøgelse | Data Mining hjælper kriminalitetsundersøgelsesbureauer med at indsætte politiets arbejdsstyrke (hvor er en forbrydelse mest sandsynligt, og hvornår?), hvem der skal søge ved en grænseovergang osv. |
| Bioinformatik | Data Mining hjælper med at udvinde biologiske data fra massive datasæt indsamlet i biologi og medicin. |
Resume:
- data mining definition: Data Mining handler om at forklare fortiden og forudsige fremtiden via dataanalyse.
- Data mining hjælper med at udtrække information fra store datasæt. Det er proceduren for minedrift viden fra data.
- Data mining proces omfatter forretningsforståelse, Data forståelse, data forberedelse, modellering, Evolution, implementering.
- vigtige data mining teknikker er klassificering, klyngedannelse, Regression, Associeringsregler, ydre detektion, sekventielle mønstre og forudsigelse
- R-sprog og Oracle Data Mining er fremtrædende data mining værktøjer og teknikker.
- Data mining teknik hjælper virksomheder med at få videnbaseret information.
- den største ulempe ved data mining er, at mange analyseprogrammer er vanskelige at betjene og kræver forudgående træning for at arbejde på.
- Data mining bruges i forskellige brancher såsom kommunikation, forsikring, uddannelse, fremstilling, Bank, detailhandel, tjenesteudbydere, e-handel, supermarkeder Bioinformatik.