KDnuggets
în orice document text, există termeni specifici care reprezintă entități specifice care sunt mai informative și au un context unic. Aceste entități sunt cunoscute sub numele de entități numite , care se referă mai precis la termeni care reprezintă obiecte din lumea reală, cum ar fi oameni, locuri, organizații și așa mai departe, care sunt adesea notate cu nume proprii. O abordare naivă ar putea fi găsirea acestora uitându-se la frazele substantive din documentele text. Recunoașterea entității numite (NER) , cunoscută și sub numele de chunking/extracție a entității , este o tehnică populară utilizată în extragerea informațiilor pentru a identifica și segmenta entitățile numite și a le clasifica sau clasifica în diferite clase predefinite.
SpaCy are câteva capacități excelente pentru recunoașterea entității numite. Să încercăm să-l folosim pe unul dintre articolele noastre de știri.

vizualizarea entităților numite într-un articol de știri cu spaCy
putem vedea clar că entitățile majore numite au fost identificate prin spacy. Pentru a înțelege mai detaliat ce înseamnă fiecare entitate numită, puteți consulta documentația sau consultați următorul tabel pentru comoditate.
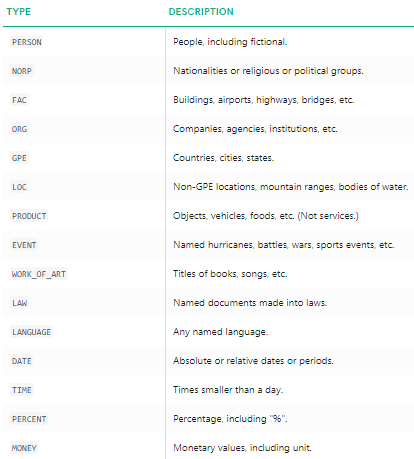
tipuri de entități numite
să aflăm acum cele mai frecvente entități numite din corpusul nostru de știri! Pentru aceasta, vom construi un cadru de date al tuturor entităților numite și tipurile acestora folosind următorul cod.
acum putem transforma și agrega acest cadru de date pentru a găsi entitățile și tipurile care apar în partea de sus.

entități și tipuri de top numite în corpusul nostru de știri
observați ceva interesant? (Sugestie: Poate presupusul summit dintre Trump și Kim Jong!). De asemenea, vedem că a identificat corect ‘Messenger’ ca produs (de pe Facebook).
de asemenea, putem grupa după tipurile de entități pentru a înțelege ce tipuri de entități apar cel mai mult în corpusul nostru de știri.

tipuri de entități numite de top în corpusul nostru de știri
putem vedea că oamenii, locurile și organizațiile sunt cele mai menționate entități, deși interesant avem și multe alte entități.
Un alt tagger NER frumos esteStanfordNERTagger disponibil de lanltkinterfață. Pentru aceasta, trebuie să aveți instalat Java și apoi să descărcați resursele Stanford NER. Dezarhivați-le într-o locație la alegere (am folosit E:/stanford în sistemul meu).recunoașterea entității numită de Stanford se bazează pe o implementare a modelelor de secvență de câmp aleatoriu condițional cu lanț liniar (CRF). Din păcate, acest model este instruit numai pe cazuri de persoane, tipuri de organizare și locație. Următorul cod poate fi folosit ca un flux de lucru standard care ne ajută să extragem entitățile numite folosind acest tagger și să afișăm entitățile numite de sus și tipurile acestora (extracția diferă ușor de spacy).
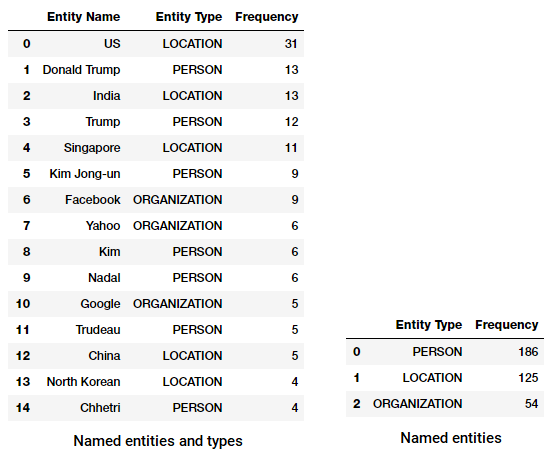
entități și tipuri de top numite de la Stanford NER pe corpusul nostru de știri
observăm rezultate destul de similare, deși limitate la doar trei tipuri de entități numite. Interesant, vom vedea un număr de menționat de mai multe persoane în diverse sporturi.
Bio: Dipanjan Sarkar este un om de știință de date @Intel, un autor, un mentor @Springboard, un scriitor și un dependent de sport și sitcom.
Original. Repostat cu permisiune.
Related:
- Modele robuste Word2Vec cu Gensim & aplicarea caracteristicilor Word2Vec pentru sarcini de învățare automată
- învățarea automată interpretabilă umană (Partea 1) — necesitatea și importanța interpretării modelului
- implementarea metodelor de învățare profundă și Ingineria caracteristicilor pentru date Text: Modelul Skip-gram