KDnuggets
em qualquer documento de texto, existem termos particulares que representam entidades específicas que são mais informativas e têm um contexto único. Essas entidades são conhecidas como entidades nomeadas, que mais especificamente se referem a termos que representam objetos do mundo real como pessoas, lugares, organizações, e assim por diante, que são frequentemente denotadas por nomes próprios. Uma abordagem ingênua poderia ser encontrá-los olhando para as frases substantivas em documentos de texto. Entity recognition (NER) , também conhecido como entity chunking/extraction , é uma técnica popular usada na extração de informações para identificar e segmentar as entidades nomeadas e classificá-las em várias classes pré-definidas.
SpaCy tem algumas excelentes capacidades para o reconhecimento de entidades nomeado. Vamos tentar usá-lo num dos nossos artigos de notícias.

Visualização de entidades nomeadas em um artigo de notícias com spaCy
Podemos ver claramente que as principais entidades nomeadas foram identificados pela tag spacy. Para entender mais em detalhes sobre o que cada entidade nomeada significa, você pode se referir à documentação ou verificar a seguinte tabela por conveniência.
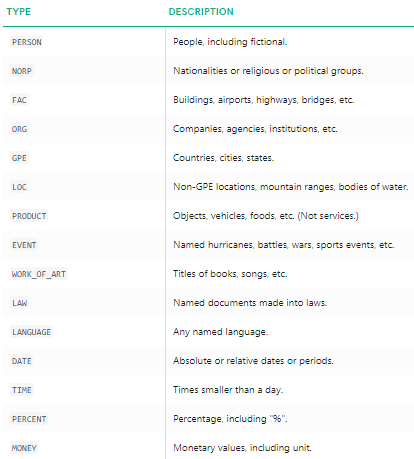
Nomeados tipos de entidade
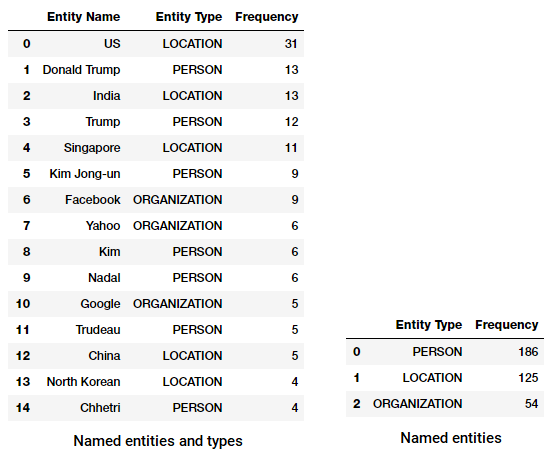
Vamos agora descobrir mais freqüentes de entidades nomeadas em nosso corpus! Para isso, vamos construir um quadro de dados de todas as entidades nomeadas e seus tipos usando o seguinte código.
Agora podemos transformar e agregar este quadro de dados para encontrar as entidades e tipos mais importantes.

Top named entities and types in our news corpus
notam alguma coisa interessante? (Dica: Talvez o suposto encontro entre Trump e Kim Jong!). Também vemos que ele identificou corretamente “mensageiro” como um produto (do Facebook).
também podemos agrupar-nos pelos tipos de Entidades para ter uma noção dos tipos de Entidades que ocorrem mais no nosso corpo de notícias.

parte Superior denominada tipos de entidade em nosso corpus
podemos ver que pessoas, lugares e organizações são as mais referidas entidades que, curiosamente, também temos muitas outras entidades.
outro bom tagger é o StanfordNERTagger disponível na interface nltk. Para isso, você precisa ter Java instalado e, em seguida, baixar os recursos Stanford NER. Desaperta – os para um local à sua escolha (usei E:/stanford no meu sistema).
o reconhecedor de entidades nomeado de Stanford é baseado em uma implementação de modelos de sequência de campo Aleatório condicional em cadeia linear (CRF). Infelizmente, este modelo só é treinado em casos de pessoas, organização e tipos de localização. O código seguinte pode ser usado como um fluxo de trabalho padrão que nos ajuda a extrair as entidades nomeadas usando este tagger e mostrar as entidades nomeadas de topo e seus tipos (a extração difere ligeiramente de spacy).
parte Superior chamada entidades e tipos de Stanford NER sobre as nossas novidades corpus
Podemos notar bastante a resultados semelhantes, embora restrita a apenas três tipos de entidades nomeadas. Curiosamente, vemos uma série de pessoas mencionadas em vários esportes.
Bio: Dipanjan Sarkar é um cientista de dados @Intel, um autor, um mentor @Springboard, um escritor, e um viciado em esportes e sitcom.Original. Reposto com permissão.
Relacionados:
- Robusto Word2Vec Modelos com Gensim & Aplicar Word2Vec Recursos para a Máquina de Tarefas de Aprendizagem
- Humanos Interpretáveis de Aprendizagem de Máquina (Parte 1) — a Necessidade e A Importância do Modelo de Interpretação
- a Implementação de Profundas Métodos de Aprendizagem e Recurso de Engenharia para Dados de Texto: O Skip-grama Modelo