KDnuggets
w każdym dokumencie tekstowym są określone terminy, które reprezentują określone jednostki, które są bardziej pouczające i mają unikalny kontekst. Byty te są znane jako nazwane byty , które dokładniej odnoszą się do terminów reprezentujących rzeczywiste obiekty, takie jak ludzie, miejsca, organizacje itp., które często są oznaczone nazwami własnymi. Naiwnym podejściem może być znalezienie ich poprzez spojrzenie na frazy rzeczownikowe w dokumentach tekstowych. Rozpoznawanie nazwanych jednostek (NER) , znane również jako wycinanie/wyodrębnianie jednostek , jest popularną techniką stosowaną w ekstrakcji informacji do identyfikowania i segmentowania nazwanych jednostek oraz klasyfikowania lub kategoryzowania ich w różnych predefiniowanych klasach.
SpaCy ma kilka doskonałych możliwości rozpoznawania nazwanych jednostek. Spróbujmy użyć go w jednym z naszych przykładowych artykułów.

Wizualizacja nazwanych podmiotów w artykule prasowym o spacji
wyraźnie widać, że główne nazwane jednostki zostały zidentyfikowane przez spacy. Aby lepiej zrozumieć, co oznacza każdy nazwany podmiot, możesz zapoznać się z dokumentacją lub dla wygody zapoznać się z poniższą tabelą.
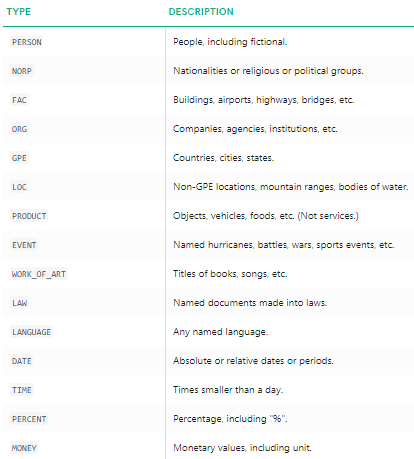
nazwane typy jednostek
sprawdźmy teraz najczęstsze nazwane jednostki w naszym korpusie wiadomości! W tym celu zbudujemy ramkę danych wszystkich nazwanych jednostek i ich typów za pomocą następującego kodu.
możemy teraz przekształcać i agregować tę ramkę danych, aby znaleźć najwyższe występujące encje i typy.

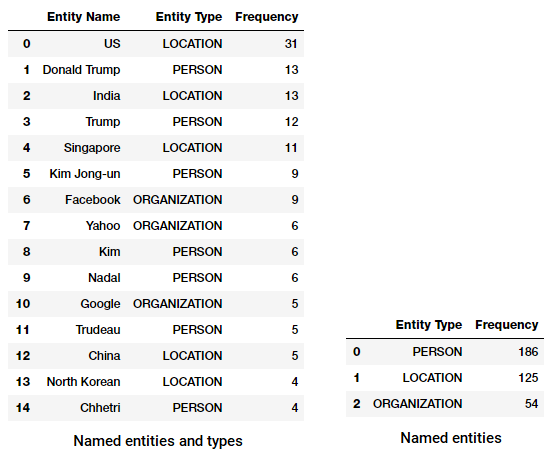
najpopularniejsze podmioty i typy w naszym korpusie wiadomości
zauważyłeś coś ciekawego? (Podpowiedź: Może rzekomy szczyt między Trumpem a Kim Dzong!). Widzimy również, że poprawnie zidentyfikował „Messenger”jako produkt (z Facebooka).
możemy również grupować według typów encji, aby uzyskać poczucie, jakie typy encji występują najczęściej w naszym korpusie wiadomości.

Top nazwane typy jednostek w naszym korpusie aktualności
widzimy, że ludzie, miejsca i organizacje są najczęściej wymienianymi podmiotami, choć co ciekawe mamy również wiele innych podmiotów.
kolejnym ładnym taggerem NER jestStanfordNERTagger dostępny z interfejsunltk. W tym celu musisz mieć zainstalowaną Javę, a następnie pobrać zasoby Stanford NER. Rozpakuj je do wybranej lokalizacji (użyłem E:/stanford w moim systemie).
rozpoznawanie nazw jednostek bazuje na implementacji modeli sekwencji liniowych łańcuchów warunkowych (CRF). Niestety ten model jest szkolony tylko na instancjach osób, organizacji i typów lokalizacji. Poniższy kod może być użyty jako standardowy obieg pracy, który pomaga nam wyodrębnić nazwane elementy za pomocą tego znacznika i pokazać najwyżej nazwane elementy i ich typy (ekstrakcja różni się nieco od spacy).
Top nazwane jednostki i typy ze Stanford NER w naszym korpusie wiadomości
zauważamy dość podobne wyniki, choć ograniczone tylko do trzech typów nazwanych jednostek. Co ciekawe, widzimy szereg wymienionych kilku osób w różnych dyscyplinach sportowych.
Bio: Dipanjan Sarkar jest analitykiem danych @Intel, autorem, mentorem @Springboard, pisarzem i uzależnionym od sportu i sitcomu.
oryginał. Reposted with permission.
powiązane:
- solidne modele Word2vec z Gensim&zastosowanie funkcji Word2Vec do zadań uczenia maszynowego
- Ludzkie Uczenie maszynowe (Część 1) — potrzeba i znaczenie interpretacji modelu
- wdrażanie metod głębokiego uczenia i Inżynierii funkcji dla danych tekstowych: Model Skip-gram