KDnuggets
in elk tekstdocument zijn er specifieke termen die specifieke entiteiten vertegenwoordigen die meer informatief zijn en een unieke context hebben. Deze entiteiten staan bekend als benoemde entiteiten , die meer specifiek verwijzen naar termen die objecten uit de echte wereld vertegenwoordigen, zoals Mensen, Plaatsen, Organisaties, enzovoort, die vaak worden aangeduid met Eigennamen. Een naïeve benadering zou kunnen zijn om deze te vinden door te kijken naar het zelfstandig naamwoord zinnen in tekstdocumenten. Named entity recognition (NER), ook bekend als entity chunking/extraction , is een populaire techniek die wordt gebruikt in informatie-extractie te identificeren en segmenteren van de genoemde entiteiten en classificeren of categoriseren onder verschillende vooraf gedefinieerde klassen.
SpaCy heeft een aantal uitstekende mogelijkheden voor named entity recognition. Laten we proberen en gebruiken op een van onze steekproef nieuwsartikelen.

visualiseren benoemde entiteiten in een nieuwsartikel met spaCy
we kunnen duidelijk zien dat de belangrijkste genoemde entiteiten zijn geïdentificeerd met spacy. Om meer in detail te begrijpen over wat elke genoemde entiteit betekent, kunt u voor het gemak de documentatie raadplegen of de volgende tabel bekijken.
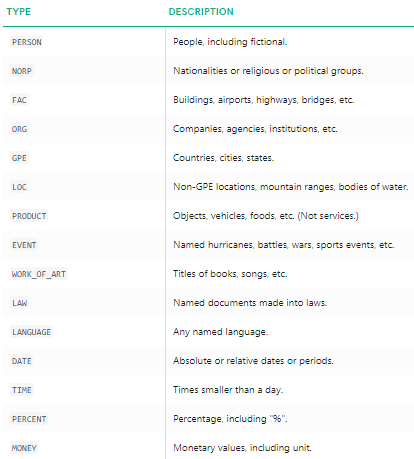
benoemde entiteitstypen
laten we nu de meest voorkomende genoemde entiteiten in ons news corpus vinden! Hiervoor bouwen we een gegevenskader op van alle genoemde entiteiten en hun typen met behulp van de volgende code.
we kunnen dit gegevensframe nu transformeren en samenvoegen om de meest voorkomende entiteiten en types te vinden.

Top genoemde entiteiten en types in ons news corpus
valt u iets interessants op? (Hint: Misschien de zogenaamde Top tussen Trump en Kim Jong!). We zien ook dat het ‘Messenger’ correct heeft geïdentificeerd als een product (van Facebook).
we kunnen ook groeperen op de entiteitstypen om een idee te krijgen van welke soorten entites het meest voorkomen in ons nieuws corpus.

Top genoemde entiteitstypen in ons news corpus
We kunnen zien dat mensen, plaatsen en organisaties de meest genoemde entiteiten zijn, hoewel we interessant genoeg ook veel andere entiteiten hebben.
een andere leuke ner tagger is deStanfordNERTagger beschikbaar via denltkinterface. Hiervoor moet u Java geïnstalleerd hebben en vervolgens de Stanford NER-bronnen Downloaden. Pak ze uit naar een locatie naar keuze (ik gebruikte E:/stanford in mijn systeem).
Stanford ‘ s Named Entity Recognizer is gebaseerd op een implementatie van lineaire Chain Conditional Random Field (CRF) sequentiemodellen. Helaas is dit model alleen getraind op gevallen van persoon, organisatie en locatie types. De volgende code kan gebruikt worden als een standaard workflow die ons helpt de genoemde entiteiten te extraheren met behulp van deze tagger en de bovenste genoemde entiteiten en hun typen te tonen (extractie verschilt enigszins van spacy).
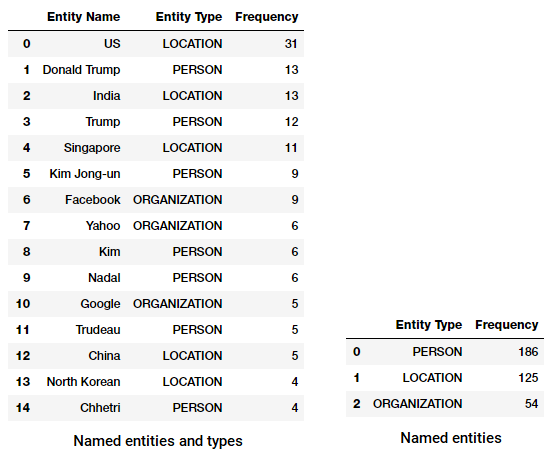
Top named entities and types from Stanford NER on our news corpus
we merken vrij vergelijkbare resultaten, hoewel beperkt tot slechts drie soorten benoemde entiteiten. Interessant, we zien een aantal van de genoemde van verschillende mensen in verschillende sporten.
Bio: Dipanjan Sarkar is een Data Scientist @Intel, een auteur, een mentor @Springboard, een schrijver, en een sport en sitcom verslaafde.
origineel. Opnieuw geplaatst met toestemming.
gerelateerd:
- robuuste Word2Vec-modellen met Gensim & Word2Vec-functies toepassen voor Machine Learning-taken
- Human Interpretable Machine Learning (Part 1) – de noodzaak en het belang van Modelinterpretatie
- implementatie van Deep Learning-methoden en Feature Engineering voor tekstgegevens: het skip-gram-Model