KDnuggets
i ethvert tekstdokument er det spesielle vilkår som representerer bestemte enheter som er mer informative og har en unik kontekst. Disse enhetene er kjent som navngitte enheter, som mer spesifikt refererer til begreper som representerer virkelige objekter som personer, steder, organisasjoner og så videre, som ofte er merket med egennavn. En naiv tilnærming kan være å finne disse ved å se på substantivfrasene i tekstdokumenter. Named entity recognition (ner), også kjent som entity chunking/extraction , er en populær teknikk som brukes i informasjonsutvinning for å identifisere og segmentere de navngitte enhetene og klassifisere eller kategorisere dem under ulike forhåndsdefinerte klasser.
SpaCy har noen gode muligheter for navngitt enhetsgjenkjenning. La oss prøve å bruke den på en av våre nyhetsartikler.

Visualisere navngitte enheter i en nyhetsartikkel med spaCy
vi kan tydelig se at de store navngitte enhetene er identifisert avspacy. For å forstå mer detaljert om hva hver navngitt enhet betyr, kan du se dokumentasjonen eller sjekke ut følgende tabell for enkelhets skyld.
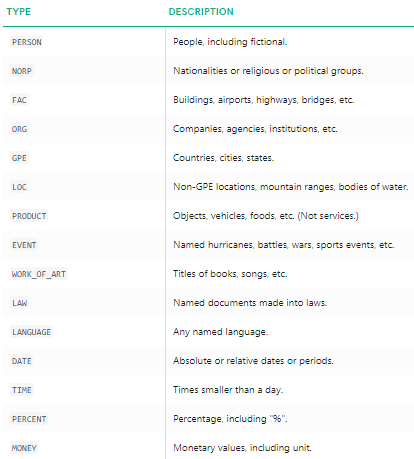
Navngitte enhetstyper
La oss nå finne ut de hyppigste navngitte enhetene i vårt nyhetskorpus! For dette vil vi bygge ut en dataramme av alle navngitte enheter og deres typer ved hjelp av følgende kode.
Vi kan nå transformere og samle denne datarammen for å finne de beste forekommende enhetene og typene.

topp navngitte enheter og typer i våre nyheter corpus
merker du noe interessant? (Hint: Kanskje det antatte toppmøtet Mellom Trump og Kim Jong!). Vi ser også at Det har riktig identifisert ‘Messenger’ som et produkt (Fra Facebook).
Vi kan også gruppere etter enhetstypene for å få en følelse av hvilke typer rettigheter som forekommer mest i vårt nyhetskorpus.

Topp navngitte entitetstyper i våre nyheter corpus
vi kan se at folk, steder og organisasjoner er de mest nevnte enhetene, men interessant nok har vi også mange andre enheter.
En annen fin ner tagger erStanfordNERTagger tilgjengelig franltkgrensesnittet. For Dette må Du Ha Java installert og deretter laste Ned Stanford ner-ressursene. Unzip dem til et sted du ønsker (jeg brukte E:/stanford i systemet mitt).Stanfords Navngitte Entity Recognizer er basert på en implementering av linear chain Conditional Random Field (CRF) sekvensmodeller. Dessverre er denne modellen kun trent på forekomster AV PERSON, ORGANISASJON og STEDSTYPER. Følgende kode kan brukes som en standard arbeidsflyt som hjelper oss med å trekke ut de navngitte enhetene ved hjelp av denne taggeren og vise de øverste navngitte enhetene og deres typer (utvinning er litt forskjellig fra spacy).
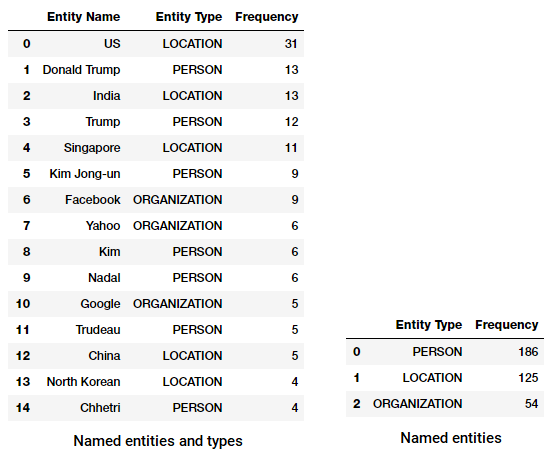
Topp navngitte enheter og typer Fra Stanford NER på våre nyheter corpus
vi merker ganske like resultater, men begrenset til bare tre typer navngitte enheter. Interessant, ser vi en rekke nevnt av flere personer i ulike idretter.
Bio: Dipanjan Sarkar Er En Data Scientist @ Intel, en forfatter, en mentor @Springboard, en forfatter, og en sport og sitcom addict.
Original. Reposted med tillatelse.
Relatert:
- Robuste Word2Vec-Modeller med Gensim & Bruk Av Word2Vec-Funksjoner for Maskinlæringsoppgaver
- Menneskelig Tolkbar Maskinlæring (Del 1 — – Behovet og Betydningen Av Modelltolkning
- Implementering Av Dype Læringsmetoder og Funksjonsteknikk for Tekstdata: Skip-gram-Modellen