KDnuggets
모든 텍스트 문서에서보다 유익하고 고유 한 컨텍스트를 가진 특정 엔티티를 나타내는 특정 용어가 있습니다. 이러한 실체로 알려져 있 라는 이름의 단체로는 더 구체적으로 약관을 참조하를 대표하는 현실 세계와 같은 개체를 사람들,장소,조직,그리고에,종종로 표시하여 적절한 이름입니다. 순진한 접근 방식은 텍스트 문서의 명사구를보고 이들을 찾는 것일 수 있습니다. 이름 entity 인식(넬),also known as entity chunking/추출기에 사용되는 기술이 정보 추출을 식별하고 세그먼트 라는 이름의 단체로 분류하거나 분류에서 그들을 다양한 사전 정의됩니다.
SpaCy 는 명명 된 엔티티 인식에 대한 우수한 기능을 가지고 있습니다. 의 시도하고 우리의 샘플 뉴스 기사 중 하나에 그것을 사용하자.

시각화하는 라는 이름의 단체에서 뉴스 기사와 적응
우리는 분명히 볼 수 있는 주요 이라는 엔티티에 의해 확인되었spacy. 각 명명 된 엔티티가 의미하는 바를 더 자세히 이해하려면 설명서를 참조하거나 편의를 위해 다음 표를 확인할 수 있습니다.
라는 이름의 entity 유형
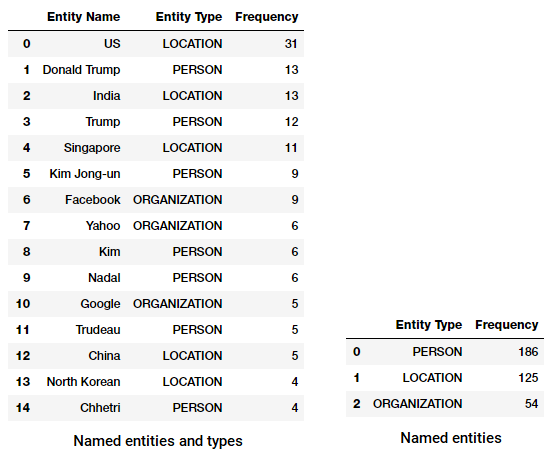
이제 가장 자주 라는 이름의 단체에서 우리의 뉴스 모음! 이를 위해 다음 코드를 사용하여 명명 된 모든 엔티티 및 해당 유형의 데이터 프레임을 작성합니다.
이제이 데이터 프레임을 변환하고 집계하여 상위 발생 엔티티 및 유형을 찾을 수 있습니다.

탑 라는 이름의 단체와 형식에서 우리의 뉴스 코퍼
시 흥미로운 것? (힌트: 어쩌면 트럼프와 김종 사이의 가정 된 정상 회담!). 우리는 또한 그것이’메신저’를 제품(Facebook 에서)으로 올바르게 식별 한 것을 봅니다.
우리는 또한 그룹 엔티티에 의해 유형의 의미는 무엇 형태의 엔터티 발생에서 가장 우리의 뉴스 corpus.

최고 명명된 엔터티를 유형에서 우리의 뉴스 코퍼
우리가 볼 수 있는 사람들,장소 및 조직에서는 가장 많이 언급한 엔지만 흥미롭게도 우리는 또한 많은 기업가를 실질적으로 지원합니다.
또 다른 멋진 NER tagger 는StanfordNERTaggernltk인터페이스입니다. 이를 위해 Java 가 설치된 다음 Stanford NER 리소스를 다운로드해야합니다. 원하는 위치에 압축을 풉니 다(시스템에서E:/stanford를 사용했습니다).
스탠포드의 명명 된 엔티티 인식기는 crf(linear chain Conditional Random Field)시퀀스 모델의 구현을 기반으로합니다. 불행히도이 모델은 사람,조직 및 위치 유형의 인스턴스에 대해서만 교육을받습니다. 다음 코드를 사용할 수 있습을 표준으로 워크플로우는 데 도움이 우리를 추출 라는 이름의 단체로 사용하는 이 술래 및 최상 라는 이름의 단체와 그들의 유형(추출시에서 약간 다릅spacy).
탑 라는 이름의 단체로 및 형태 스탠포드에서 넬에서 우리의 뉴스 코퍼
우리는 알 수 있 매우 비슷한 결과를 비록 제한하는 세 가지 유형의 라는 이름의 단체로. 흥미롭게도,우리는 다양한 스포츠에서 여러 사람들의 언급 된 숫자를 봅니다.
바이오: Dipanjan Sarkar 는 데이터 과학자@Intel,저자,멘토@Springboard,작가 및 스포츠 및 시트콤 중독자입니다.
원본. 허락을 받아 재 게시되었습니다.
관련
- 강력한 Word2Vec 모델 Gensim&을 적용하 Word2Vec 기능에 대한 기계 학습 과
- 인간의 해석할 수 있는 기계학습(Part1)—필요성과 중요성의 해석 모델
- 을 구현하는 심화 학습 방법과 기능 엔지니어링에 대한 텍스트 데이터를 건너뛰-gram 모델