KDnuggets
En cualquier documento de texto, hay términos particulares que representan entidades específicas que son más informativas y tienen un contexto único. Estas entidades se conocen como entidades con nombre , que se refieren más específicamente a términos que representan objetos del mundo real como personas, lugares, organizaciones, etc., que a menudo se denotan con nombres propios. Un enfoque ingenuo podría ser encontrarlos mirando las frases nominales en los documentos de texto. El reconocimiento de entidades con nombre (NER) , también conocido como fragmentación/extracción de entidades , es una técnica popular utilizada en la extracción de información para identificar y segmentar las entidades con nombre y clasificarlas o categorizarlas en varias clases predefinidas.
SpaCy tiene algunas capacidades excelentes para el reconocimiento de entidades con nombre. Intentemos usarlo en uno de nuestros artículos de noticias de muestra.

la Visualización de entidades con nombre en un artículo de noticias con spaCy
Podemos ver claramente que las principales entidades nombradas han sido identificados por la etiqueta spacy. Para comprender más en detalle lo que significa cada entidad nombrada, puede consultar la documentación o consultar la siguiente tabla para mayor comodidad.
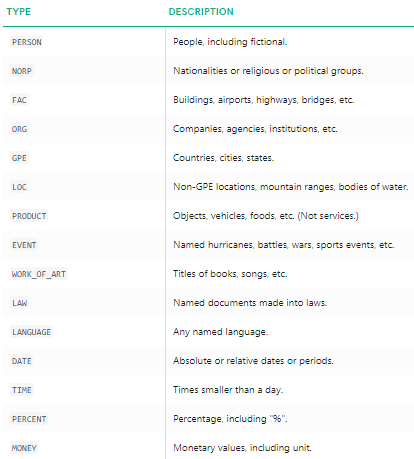
Tipos de entidades con nombre
¡Ahora descubramos las entidades con nombre más frecuentes en nuestro corpus de noticias! Para esto, construiremos un marco de datos de todas las entidades nombradas y sus tipos utilizando el siguiente código.
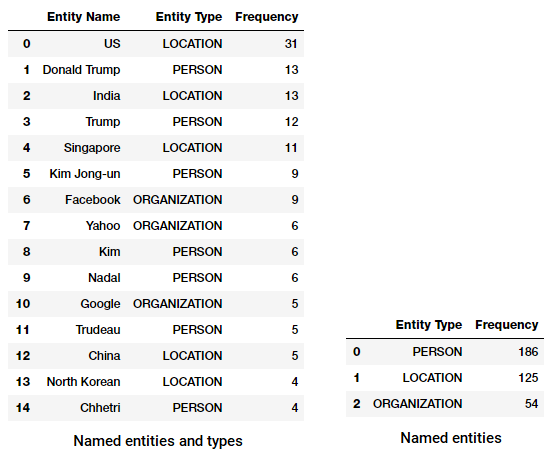
Ahora podemos transformar y agregar este marco de datos para encontrar las entidades y tipos más importantes.

Las principales entidades y tipos nombrados en nuestro corpus de noticias
¿Nota algo interesante? (Sugerencia: ¡Tal vez la supuesta cumbre entre Trump y Kim Jong!). También vemos que ha identificado correctamente a ‘Messenger’ como un producto (de Facebook).
También podemos agrupar por tipos de entidades para tener una idea de qué tipos de entidades aparecen más en nuestro corpus de noticias.

Los principales tipos de entidades con nombre en nuestro corpus de noticias
Podemos ver que las personas, lugares y organizaciones son las entidades más mencionadas, aunque curiosamente también tenemos muchas otras entidades.
Otro buen etiquetador de NER es el StanfordNERTagger disponible en la interfaz nltk. Para esto, necesita tener instalado Java y luego descargar los recursos de Stanford NER. Descomprímelos en una ubicación de su elección (utilicé E:/stanford en mi sistema).
El Reconocedor de Entidades con nombre de Stanford se basa en una implementación de modelos de secuencia de Campos Aleatorios Condicionales de Cadena lineal (CRF). Desafortunadamente, este modelo solo está capacitado en instancias de tipos de PERSONA, ORGANIZACIÓN y UBICACIÓN. El siguiente código se puede usar como un flujo de trabajo estándar que nos ayuda a extraer las entidades con nombre usando este etiquetador y mostrar las entidades con nombre superior y sus tipos (la extracción difiere ligeramente de spacy).
Las principales entidades y tipos con nombre de Stanford NER en nuestro corpus de noticias
Notamos resultados bastante similares, aunque restringidos a solo tres tipos de entidades con nombre. Curiosamente, vemos un número de personas mencionadas en varios deportes.
Bio: Dipanjan Sarkar es un científico de datos @Intel, un autor, un mentor @Springboard, un escritor y un adicto a los deportes y a las sitcom.
Original. Publicado con permiso.
Relacionados:
- Modelos Robustos de Word2Vec con Gensim&Aplicación de características de Word2Vec para Tareas de Aprendizaje Automático
- Aprendizaje Automático Interpretable por Humanos (Parte 1): La Necesidad y la Importancia de la Interpretación de Modelos
- Implementación de Métodos de Aprendizaje Profundo e Ingeniería de Características para Datos de Texto: El Modelo de Salto de gramo