KDnuggets
任意のテキストドキュメントでは、より有益でユニークなコンテキストを持つ特定のエンティティを表す特定の用語があります。 これらのエンティティは名前付きエンティティと呼ばれ、より具体的には、人、場所、組織などの現実世界のオブジェクトを表す用語を指します。 素朴なアプローチは、テキスト文書の名詞句を見ることによってこれらを見つけることです。 名前付きエンティティ認識(NER)は、名前付きエンティティを識別してセグメント化し、さまざまな事前定義されたクラスの下でそれらを分類または分類するために、情報抽出で使用される一般的な手法です。
SpaCyは、名前付きエンティティ認識のためのいくつかの優れた機能を持っています。 のは、試してみて、私たちのサンプルのニュース記事のいずれかでそれを使用してみましょう。

spaCyでニュース記事内の名前付きエンティティを視覚化
spaCyでニュース記事内の名前付きエンティティを視覚化
spaCyでニュース記事内の名前付きエンティティを視覚化
主要な名前付きエンティティがspacyによって識別されていることがはっきりとわかります。 各名前付きエンティティの意味の詳細を理解するには、ドキュメントを参照するか、便宜のために次の表を参照してください。
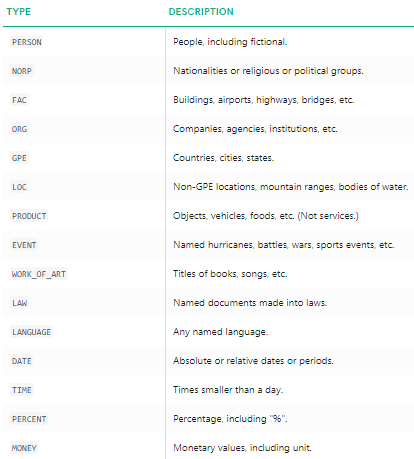
名前付きエンティティタイプ
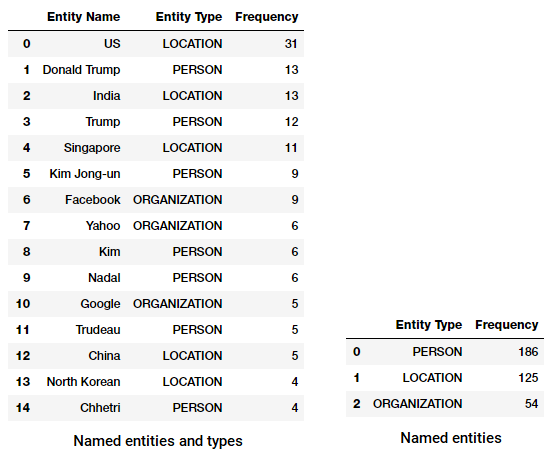
今、私たちのニュースコーパスの中で最も頻繁に名前付きエンテ このために、次のコードを使用して、すべての名前付きエンティティとその型のデータフレームを構築します。
このデータフレームを変換して集計し、発生している上位のエンティティとタイプを見つけることができます。

ニュースコーパスのトップ名前付きエンティティとタイプ
興味深いことに気づいていますか? (ヒント: たぶんトランプと金正日の間の想定される首脳会談!). また、「Messenger」を(Facebookからの)製品として正しく識別していることもわかります。facebookからの製品は、次のように表示されています。
また、エンティティタイプでグループ化して、ニュースコーパスで最も発生するエンティティのタイプを知ることもできます。

ニュースコーパスのトップ名前付きエンティティタイプ
興味深いことに、他の多くのエンティティもありますが、人、場所、組織が最も言及されているエンティティであることがわかります。別の素敵なNERタガーは、nltkStanfordNERTaggerです。 このためには、JavaをインストールしてからStanford NERリソースをダウンロードする必要があります。 それらを選択した場所に解凍します(私のシステムではE:/stanfordを使用しました)。
StanfordのNamed Entity Recognizerは、線形鎖条件付きランダムフィールド(CRF)シーケンスモデルの実装に基づいています。 残念ながら、このモデルは、PERSON、ORGANIZATION、LOCATIONタイプのインスタンスでのみ訓練されます。 次のコードは、このタガーを使用して名前付きエンティティを抽出し、上位の名前付きエンティティとそのタイプを表示するのに役立つ標準的なワークフ
私たちのニュースコーパス上のスタンフォードNERからトップ名前付きエンティティとタイプ
私たちは、名前付きエ 興味深いことに、我々は様々なスポーツでいくつかの人々の言及の数を参照してください。
バイオ: Dipanjan Sarkarは、データ科学者@Intel、著者、メンター@Springboard、作家、スポーツとシットコムの中毒者です。オリジナル。
許可を得て再投稿。
関連:
- Gensimを使用した堅牢なWord2Vecモデル&機械学習タスクにWord2Vec機能を適用する
- 人間の解釈可能な機械学習(パート1)—モデル解釈の必要性と重要性
- ディープラーニングメソッドとテキストデータの特徴工学の実装:スキップグラムモデル