KDnuggets
In qualsiasi documento di testo, ci sono termini particolari che rappresentano entità specifiche che sono più informative e hanno un contesto unico. Queste entità sono note come entità denominate, che si riferiscono più specificamente a termini che rappresentano oggetti del mondo reale come persone, luoghi, organizzazioni e così via, che sono spesso indicati con nomi propri. Un approccio ingenuo potrebbe essere quello di trovare questi guardando le frasi sostantivi nei documenti di testo. Named Entity recognition (NER) , noto anche come entity chunking/extraction , è una tecnica popolare utilizzata nell’estrazione delle informazioni per identificare e segmentare le entità nominate e classificarle o classificarle in varie classi predefinite.
SpaCy ha alcune funzionalità eccellenti per il riconoscimento di entità con nome. Proviamo ad usarlo su uno dei nostri articoli di notizie di esempio.

Visualizzazione entità con nome in un articolo di notizie con spaCy
Possiamo vedere chiaramente che la maggiore entità con nome sono stati identificati spacy. Per capire più in dettaglio cosa significa ciascuna entità nominata, è possibile fare riferimento alla documentazione o controllare la seguente tabella per comodità.
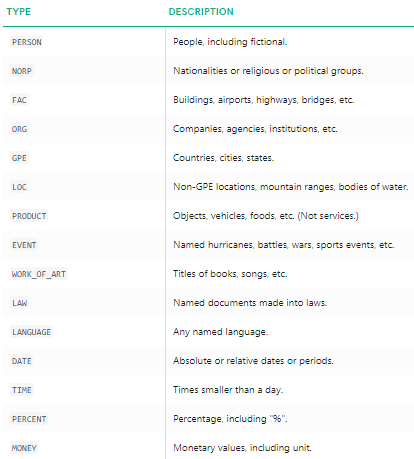
Tipi di entità nominate
Scopriamo ora le entità nominate più frequenti nel nostro news corpus! Per questo, costruiremo un frame di dati di tutte le entità nominate e dei loro tipi utilizzando il seguente codice.
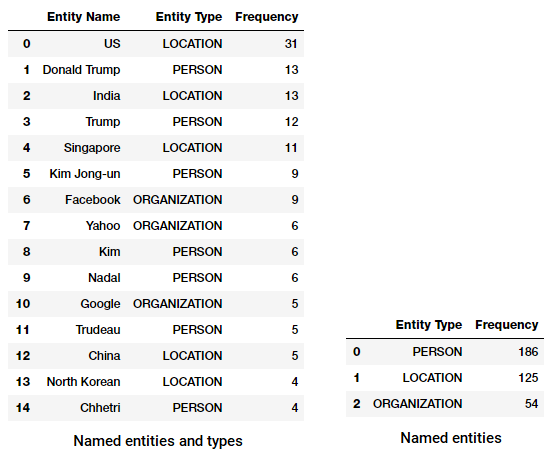
Ora possiamo trasformare e aggregare questo frame di dati per trovare le entità e i tipi più importanti.

Le entità e i tipi più citati nel nostro news corpus
Notate qualcosa di interessante? (Suggerimento: Forse il presunto vertice tra Trump e Kim Jong!). Vediamo anche che ha correttamente identificato ‘Messenger’ come un prodotto (da Facebook).
Possiamo anche raggruppare in base ai tipi di entità per avere un’idea di quali tipi di entità si verificano maggiormente nel nostro corpus di notizie.

Tipi di entità top named nel nostro news corpus
Possiamo vedere che le persone, i luoghi e le organizzazioni sono le entità più menzionate anche se è interessante notare che abbiamo anche molte altre entità.
Un altro bel tagger NER è il StanfordNERTagger disponibile dal nltkinterfaccia. Per questo, è necessario disporre di Java installato e quindi scaricare le risorse di Stanford NER. Decomprimili in una posizione a tua scelta (ho usato E:/stanford nel mio sistema).
Il Named Entity Recognizer di Stanford si basa su un’implementazione di modelli di sequenza CRF (Conditional Random Field) a catena lineare. Sfortunatamente questo modello viene addestrato solo su istanze di tipi di PERSONA, ORGANIZZAZIONE e POSIZIONE. Il seguente codice può essere utilizzato come flusso di lavoro standard che ci aiuta a estrarre le entità nominate usando questo tagger e mostrare le entità nominate in alto e i loro tipi (l’estrazione differisce leggermente da spacy).
Top named entities and types from Stanford NER sul nostro news corpus
Notiamo risultati abbastanza simili anche se limitati a soli tre tipi di entità con nome. È interessante notare che, vediamo un certo numero di menzionato di diverse persone in vari sport.
Bio: Dipanjan Sarkar è un Data Scientist @ Intel ,un autore ,un mentore @ Springboard, uno scrittore e un tossicodipendente sportivo e sitcom.
Originale. Ripubblicato con il permesso.
Correlati:
- Modelli Word2Vec robusti con Gensim& Applicazione delle funzionalità Word2Vec per attività di apprendimento automatico
- Apprendimento automatico interpretabile umano (parte 1) – La necessità e l’importanza dell’interpretazione del modello
- Implementazione di metodi di apprendimento profondo e ingegneria delle funzionalità per i dati di testo: Il modello Skip-gram