KDnuggets
bármely szöveges dokumentumban vannak olyan kifejezések, amelyek olyan konkrét entitásokat képviselnek, amelyek informatívabbak, és egyedi kontextussal rendelkeznek. Ezeket az entitásokat elnevezett entitásoknak nevezik, amelyek pontosabban olyan kifejezésekre utalnak, amelyek valós objektumokat képviselnek, mint az emberek, helyek, szervezetek stb., amelyeket gyakran megfelelő nevek jelölnek. Naiv megközelítés lehet ezeket megtalálni a szöveges dokumentumokban szereplő főnév-mondatok megtekintésével. A megnevezett entitás-felismerés (ner) , más néven entitás-darabolás/ – kitermelés , egy népszerű módszer, amelyet az információkitermelésben használnak a megnevezett entitások azonosítására és szegmensére, valamint különféle előre meghatározott osztályok alá osztályozására vagy kategorizálására.
a SpaCy kiváló képességekkel rendelkezik a megnevezett entitásfelismeréshez. Próbáljuk meg használni az egyik minta hírcikkünkben.

Megjelenítő nevű szervezetek egy cikket a hóbortos
Világosan láthatjuk, hogy az őrnagy nevű szervezetek azonosítottak a spacy. Ha részletesebben meg szeretné tudni, hogy mit jelent az egyes megnevezett entitás, olvassa el a dokumentációt, vagy nézze meg az alábbi táblázatot a kényelem érdekében.
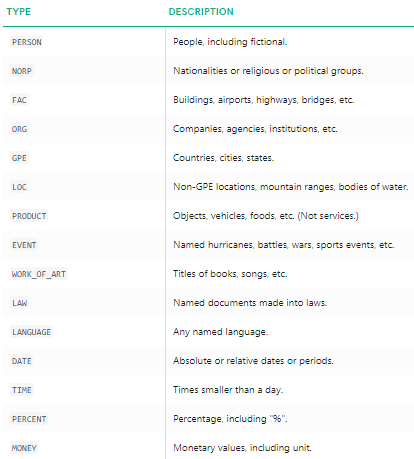
megnevezett entitás típusok
corpus most találjuk meg a leggyakoribb megnevezett entitásokat a híreinkben! Ehhez egy adatkeretet építünk ki az összes megnevezett entitásból és azok típusából a következő kód segítségével.
ezt az adatkeretet most átalakíthatjuk és összevonhatjuk, hogy megtaláljuk a legfontosabb előforduló entitásokat és típusokat.

A hírek corpus
észrevesz valami érdekeset? (Tipp: Talán a Trump és Kim Dzsong közötti állítólagos csúcstalálkozó!). Azt is látjuk, hogy helyesen azonosította a “Messenger” terméket (a Facebook-tól).
csoportosíthatjuk az entitástípusokat is, hogy megértsük, milyen típusú entitások fordulnak elő leginkább a hírtestünkben.

top megnevezett entitástípusok a news corpus
láthatjuk, hogy az emberek, helyek és szervezetek a leggyakrabban említett entitások, bár érdekes módon sok más entitásunk is van.
egy másik szép NER tagger a StanfordNERTagger elérhető a nltkfelületről. Ehhez telepítenie kell a Java-t, majd le kell töltenie a Stanford Ner erőforrásait. Csomagolja ki őket az Ön által választott helyre (a rendszeremben a E:/stanford – ot használtam).
A Stanford nevű Entity Recognizer a lineáris lánc feltételes véletlen mező (CRF) szekvencia modellek megvalósításán alapul. Sajnos ez a modell csak személy -, szervezet-és HELYTÍPUSOKRA képzett. Következő kódot lehet használni, mint egy szabványos munkafolyamat, amely segít kivonat a megnevezett entitások ezzel tagger, valamint azt mutatják, a felső megnevezett entitások és azok típusai(extraction kissé eltér spacy).
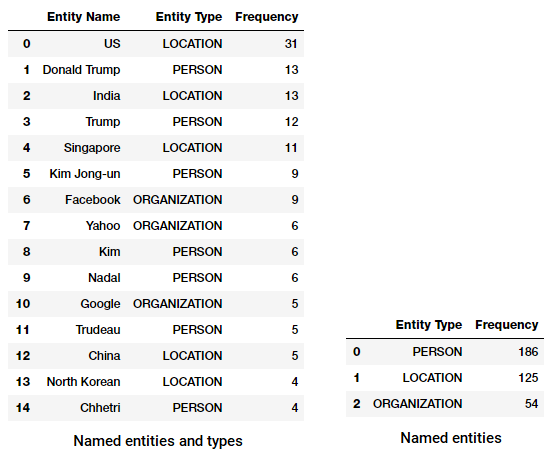
Top megnevezett entitások és típusok a Stanford NER-től a news corpus
hasonló eredményeket észlelünk, bár csak három megnevezett entitásra korlátozódunk. Érdekes, hogy számos említett embert látunk a különböző sportokban.
Bio: Dipanjan Sarkar egy Adattudós @Intel, egy szerző, egy mentor @ugródeszka, egy író, és egy sport és sitcom rabja.
eredeti. Reposted engedélyével.
kapcsolódó:
- robusztus Word2Vec modellek Gensim & A Word2Vec funkciók alkalmazása gépi tanulási feladatokhoz
- emberi értelmezhető Gépi tanulás — 1. rész) – a modell értelmezésének szükségessége és fontossága
- mély tanulási módszerek és Funkciótervezés a szöveges adatokhoz: a Skip-gram modell