KDnuggets
Dans tout document texte, il existe des termes particuliers qui représentent des entités spécifiques qui sont plus informatifs et ont un contexte unique. Ces entités sont connues sous le nom d’entités nommées, qui se réfèrent plus spécifiquement à des termes qui représentent des objets du monde réel tels que des personnes, des lieux, des organisations, etc., qui sont souvent désignés par des noms propres. Une approche naïve pourrait être de les trouver en regardant les phrases nominales dans les documents texte. La reconnaissance d’entités nommées (NER), également connue sous le nom de découpage/ extraction d’entités, est une technique populaire utilisée dans l’extraction d’informations pour identifier et segmenter les entités nommées et les classer ou les classer dans diverses classes prédéfinies.
SpaCy a d’excellentes capacités pour la reconnaissance d’entités nommées. Essayons de l’utiliser sur l’un de nos exemples d’articles de presse.

Visualiser des entités nommées dans un article de presse avec spaCy
Nous pouvons clairement voir que les principales entités nommées ont été identifiées par spacy. Pour comprendre plus en détail ce que signifie chaque entité nommée, vous pouvez vous référer à la documentation ou consulter le tableau suivant pour plus de commodité.
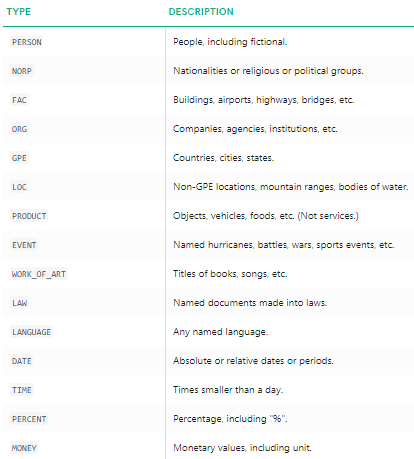
Types d’entités nommées
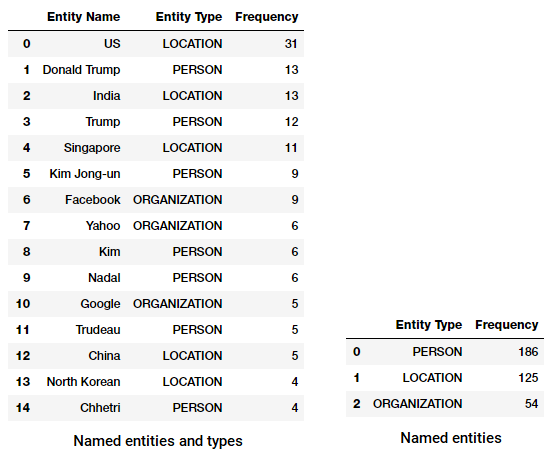
Découvrons maintenant les entités nommées les plus fréquentes dans notre corpus d’actualités! Pour cela, nous allons construire un bloc de données de toutes les entités nommées et de leurs types en utilisant le code suivant.
Nous pouvons maintenant transformer et agréger ce bloc de données pour trouver les entités et les types les plus fréquents.

Les principales entités et types nommés dans notre corpus d’actualités
Remarquez-vous quelque chose d’intéressant? (Allusion: Peut-être le sommet supposé entre Trump et Kim Jong!). Nous voyons également qu’il a correctement identifié ‘Messenger’ comme un produit (de Facebook).
Nous pouvons également regrouper par types d’entités pour avoir une idée des types d’entités qui se produisent le plus dans notre corpus d’actualités.

Les types d’entités les plus nommés dans notre corpus d’actualités
Nous pouvons voir que les personnes, les lieux et les organisations sont les entités les plus mentionnées, bien qu’il soit intéressant de noter que nous avons également de nombreuses autres entités.
Un autre tagueur NER intéressant est l’interface StanfordNERTagger disponible à partir de l’interface nltk. Pour cela, vous devez installer Java, puis télécharger les ressources Stanford NER. Décompressez-les à l’emplacement de votre choix (j’ai utilisé E:/stanford dans mon système).
Le logiciel de reconnaissance d’entités nommé de Stanford est basé sur une implémentation de modèles de séquences de Champs aléatoires conditionnels en chaîne linéaire (CRF). Malheureusement, ce modèle n’est formé que sur des instances de type PERSONNE, ORGANISATION et LIEU. Le code suivant peut être utilisé comme un flux de travail standard qui nous aide à extraire les entités nommées à l’aide de ce tagger et à afficher les entités nommées les plus hautes et leurs types (l’extraction diffère légèrement de spacy).
Les principales entités et types nommés de Stanford NER sur notre corpus d’actualités
Nous remarquons des résultats assez similaires bien que limités à seulement trois types d’entités nommées. Fait intéressant, nous voyons un certain nombre de personnes mentionnées dans divers sports.
Bio: Dipanjan Sarkar est un scientifique des données @ Intel, un auteur, un mentor @ Springboard, un écrivain et un passionné de sports et de sitcom.
Original. Republié avec permission.
Connexes:
- Modèles Word2Vec robustes avec Gensim &Application des Fonctionnalités Word2Vec pour les Tâches d’Apprentissage Automatique
- Apprentissage Automatique Interprétable par l’Homme (Partie 1) — La Nécessité et l’Importance de l’Interprétation des Modèles
- Mise en œuvre de Méthodes d’Apprentissage Profond et d’Ingénierie des Fonctionnalités pour les Données Textuelles: Le Modèle Skip-gram