kdnuggets
missä tahansa tekstidokumentissa on erityisiä termejä, jotka edustavat tietynlaisia kokonaisuuksia, jotka ovat informatiivisempia ja joilla on ainutlaatuinen konteksti. Näitä entiteettejä kutsutaan nimetyiksi entiteeteiksi , jotka tarkemmin tarkoittavat termejä, jotka edustavat reaalimaailman kohteita, kuten ihmisiä, paikkoja, organisaatioita ja niin edelleen, joita usein merkitään erisnimillä. Naiivi lähestymistapa voisi olla löytää nämä katsomalla substantiivilausekkeita tekstidokumenteissa. Nimetty entiteetti tunnustaminen (ner) , joka tunnetaan myös nimellä entity chunking/extraction , on suosittu tekniikka, jota käytetään tiedon louhinta tunnistaa ja segmentoida nimetty yhteisöt ja luokitella tai luokitella ne eri ennalta luokkiin.
Spacylla on erinomaisia kykyjä nimetyn entiteetin tunnistamiseen. Yritetään käyttää sitä yksi näyte uutisia.

nimettyjen entiteettien visualisointi uutisartikkelissa spaCy
voidaan selvästi nähdä, että tärkeimmät nimetyt entiteetit on yksilöityspacy. Jos haluat ymmärtää tarkemmin, mitä kukin nimetty yksikkö tarkoittaa, voit viitata dokumentaatioon tai tarkistaa seuraavan taulukon mukavuussyistä.
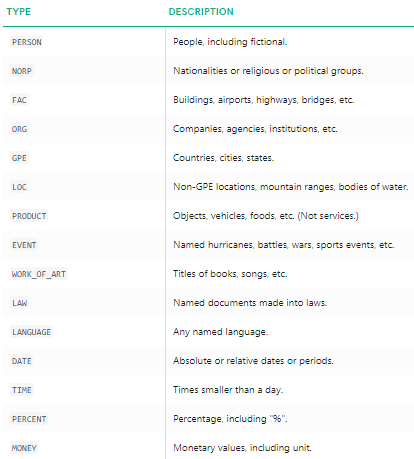
nimetyt entiteettityypit
selvitetään nyt useimmin nimetyt entiteetit uutiskorpuksessamme! Tätä varten rakennamme tietokehyksen kaikista nimetyistä yhteisöistä ja niiden tyypeistä käyttäen seuraavaa koodia.
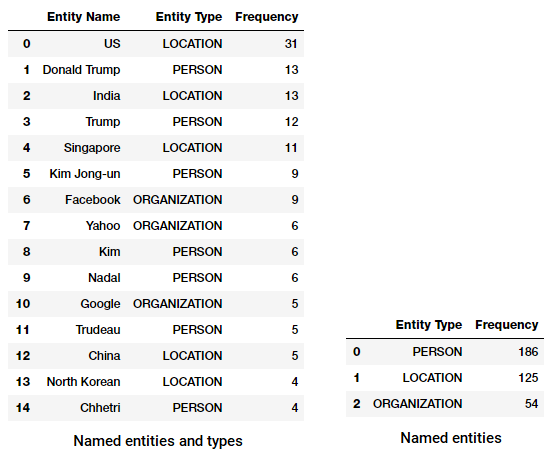
voimme nyt muuttaa ja koota tätä tietokehystä löytääksemme huippuyksilöitä ja-tyyppejä.

Uutiskorpuksessamme nimetyt kokonaisuudet ja tyypit
huomaatko mitään kiinnostavaa? (Vihje: Ehkä Trumpin ja Kim Jongin oletettu huippukokous!). Näemme myös, että se on oikein tunnistanut ”Messenger” tuotteeksi (Facebookista).
voimme myös ryhmitellä entiteettityyppejä saadaksemme käsityksen siitä, millaisia entiteettejä esiintyy eniten uutiskorpuksessamme.

Kärkinimiset entiteettityypit uutiskorpuksessamme
voimme nähdä, että ihmiset, paikat ja organisaatiot ovat eniten mainittuja entiteettejä, vaikka mielenkiintoista on, että meillä on myös monia muita entiteettejä.
toinen kiva NER-tagger on StanfordNERTagger saatavilla nltk – liittymästä. Tätä varten, sinun täytyy olla Java asennettuna ja lataa Stanford ner resursseja. Pura ne haluamaasi paikkaan (käytin järjestelmässäni E:/stanford).
Stanfordin nimetty Entity Recognizer perustuu linear chain Conditional Random Field (CRF) – sekvenssimallien toteuttamiseen. Valitettavasti tämä malli on vain koulutettu tapauksissa henkilö, organisaatio ja sijainti tyyppejä. Seuraavaa koodia voidaan käyttää standardina työnkulkuna, joka auttaa meitä poimimaan nimetyt entiteetit tällä tagerilla ja näyttämään ylimmät nimetyt entiteetit ja niiden tyypit (extraction eroaa hieman spacy).
Stanfordin parhaiksi nimetyt entiteetit ja tyypit uutiskorpuksessamme
huomaamme melko samanlaisia tuloksia, vaikka ne rajoittuvat vain kolmentyyppisiin nimettyihin entiteetteihin. Mielenkiintoista, näemme useita mainittu useita ihmisiä eri urheilulajeissa.
Bio: Dipanjan Sarkar on Datatieteilijä @Intel, kirjailija, mentori @ponnahduslauta, kirjailija sekä urheilu-ja komediaaddikti.
Alkuperäinen. Lähetetään uudelleen luvalla.
Related:
- Robust Word2Vec Models with Gensim & Word2Vec — ominaisuuksien soveltaminen Koneoppimistehtäviin
- ihmisen tulkittava Koneoppiminen (Osa 1)-Mallitulkinnan tarve ja merkitys
- Syväoppimismenetelmien ja tekstitietojen Ominaisuustekniikan toteuttaminen: Skip-gram-malli