KDnuggets
In jedem Textdokument gibt es bestimmte Begriffe, die bestimmte Entitäten darstellen, die informativer sind und einen eindeutigen Kontext haben. Diese Entitäten werden als benannte Entitäten bezeichnet , die sich genauer auf Begriffe beziehen, die reale Objekte wie Personen, Orte, Organisationen usw. darstellen, die häufig mit Eigennamen bezeichnet werden. Ein naiver Ansatz könnte darin bestehen, diese zu finden, indem man sich die Nominalphrasen in Textdokumenten ansieht. Named Entity Recognition (NER) , auch bekannt als Entity Chunking / Extraction , ist eine beliebte Technik, die bei der Informationsextraktion verwendet wird, um die benannten Entitäten zu identifizieren und zu segmentieren und sie unter verschiedenen vordefinierten Klassen zu klassifizieren oder zu kategorisieren.
SpaCy verfügt über einige hervorragende Funktionen zur Erkennung benannter Entitäten. Versuchen wir es in einem unserer Beispiel-Nachrichtenartikel.

Visualisierung benannter Entitäten in einem Nachrichtenartikel mit spaCy
Wir können deutlich sehen, dass die wichtigsten benannten Entitäten durch spacy identifiziert wurden. Um genauer zu verstehen, was jede benannte Entität bedeutet, können Sie die Dokumentation lesen oder der Einfachheit halber die folgende Tabelle lesen.
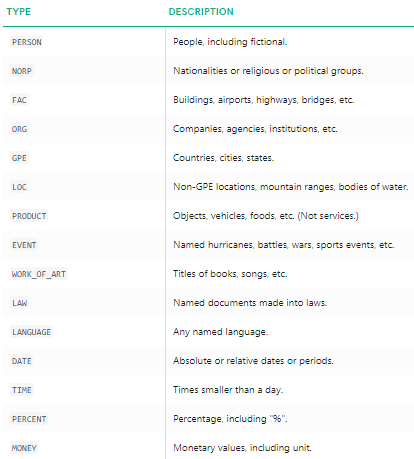
Benannte Entitätstypen
Lassen Sie uns nun die häufigsten benannten Entitäten in unserem News-Korpus herausfinden! Dazu werden wir einen Datenrahmen aller benannten Entitäten und ihrer Typen mit dem folgenden Code erstellen.
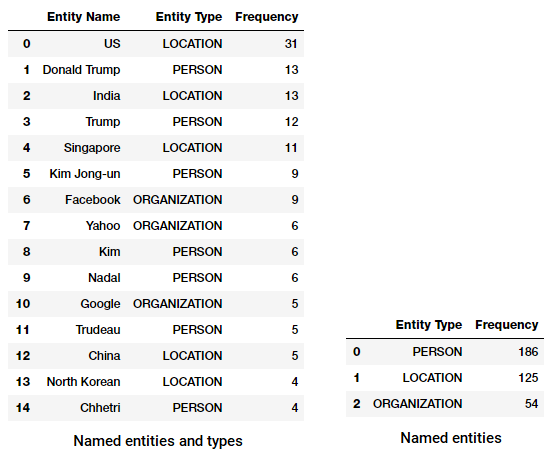
Wir können diesen Datenrahmen jetzt transformieren und aggregieren, um die am häufigsten vorkommenden Entitäten und Typen zu finden.

Top benannte Entitäten und Typen in unserem News-Korpus
Haben Sie etwas Interessantes bemerkt? (Hinweis: Vielleicht der vermeintliche Gipfel zwischen Trump und Kim Jong!). Wir sehen auch, dass es ‚Messenger‘ korrekt als Produkt (von Facebook) identifiziert hat.
Wir können auch nach den Entitätstypen gruppieren, um ein Gefühl dafür zu bekommen, welche Arten von Entitäten in unserem News-Korpus am häufigsten vorkommen.

Top benannte Entitätstypen in unserem News-Korpus
Wir können sehen, dass Menschen, Orte und Organisationen die am häufigsten genannten Entitäten sind, obwohl wir interessanterweise auch viele andere Entitäten haben.
Ein weiterer netter NER-Tagger ist die StanfordNERTagger, die über die nltk -Schnittstelle verfügbar ist. Dazu müssen Sie Java installiert haben und dann die erforderlichen NER-Ressourcen herunterladen. Entpacken Sie sie an einen Ort Ihrer Wahl (ich habe E:/stanford in meinem System verwendet).
Stanfords Named Entity Recognizer basiert auf einer Implementierung von CRF-Sequenzmodellen (Linear Chain Conditional Random Field). Leider wird dieses Modell nur auf Instanzen von PERSONEN-, ORGANISATIONS- und Standorttypen trainiert. Der folgende Code kann als Standard-Workflow verwendet werden, der uns hilft, die benannten Entitäten mit diesem Tagger zu extrahieren und die oben benannten Entitäten und ihre Typen anzuzeigen (die Extraktion unterscheidet sich geringfügig von spacy ).
Top benannte Entitäten und Typen von Stanford NER in unserem News Corpus
Wir bemerken ziemlich ähnliche Ergebnisse, obwohl sie auf nur drei Arten von benannten Entitäten beschränkt sind. Interessanterweise sehen wir eine Reihe von Verletzungen mehrerer Menschen in verschiedenen Sportarten.
Bio: Dipanjan Sarkar ist ein Data Scientist @Intel, ein Autor, ein Mentor @Springboard, ein Schriftsteller und ein Sport- und Sitcom-Süchtiger.
Original. Reposted mit Erlaubnis.
Verwandt:
- Robuste Word2Vec-Modelle mit Gensim & Anwenden von Word2Vec-Funktionen für maschinelle Lernaufgaben
- Menschlich interpretierbares maschinelles Lernen (Teil 1) – Die Notwendigkeit und Bedeutung der Modellinterpretation
- Implementierung von Deep-Learning-Methoden und Feature-Engineering für Textdaten: Das Skip-Gram-Modell