KDnuggets
i ethvert tekstdokument er der særlige udtryk, der repræsenterer specifikke enheder, der er mere informative og har en unik kontekst. Disse enheder er kendt som navngivne enheder , der mere specifikt henviser til udtryk, der repræsenterer objekter i den virkelige verden som mennesker, steder, organisationer og så videre, som ofte betegnes med egentlige navne. En naiv tilgang kan være at finde disse ved at se på substantivfraserne i tekstdokumenter. Navngivet enhedsgenkendelse (NER), også kendt som enhed chunking/ekstraktion, er en populær teknik, der bruges i informationsekstraktion til at identificere og segmentere de navngivne enheder og klassificere eller kategorisere dem under forskellige foruddefinerede klasser.
SpaCy har nogle fremragende muligheder for navngivne enhed anerkendelse. Lad os prøve at bruge det på en af vores eksempler på nyhedsartikler.

visualisering af navngivne enheder i en nyhedsartikel med spaCy
Vi kan tydeligt se, at de store navngivne enheder er blevet identificeret af spacy. For at forstå mere detaljeret om, hvad hver navngivet enhed betyder, Kan du henvise til dokumentationen eller tjekke nedenstående tabel for nemheds skyld.
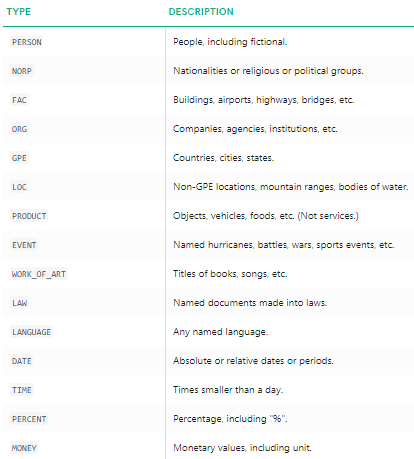
navngivne enhedstyper
lad os nu finde ud af de hyppigste navngivne enheder i vores nyhedskorpus! Til dette vil vi opbygge en dataramme af alle de navngivne enheder og deres typer ved hjælp af følgende kode.
Vi kan nu transformere og samle denne dataramme for at finde de mest forekommende enheder og typer.

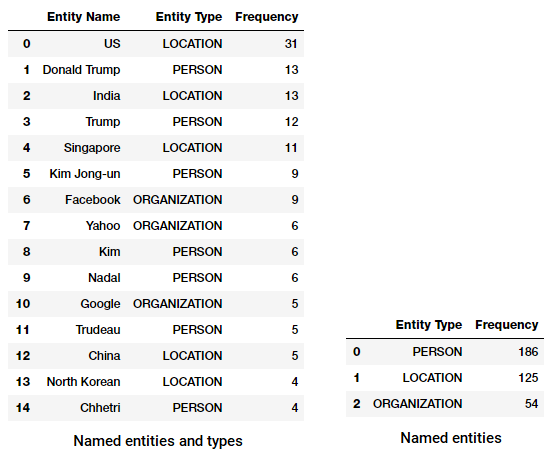
Top navngivne enheder og typer i vores nyheder corpus
bemærker du noget interessant? (Tip: Måske det formodede topmøde mellem Trump og Kim Jong!). Vi ser også, at det korrekt har identificeret ‘Messenger’ som et produkt (fra Facebook).
Vi kan også gruppere efter enhedstyperne for at få en fornemmelse af, hvilke typer entites der forekommer mest i vores nyhedskorpus.

Top navngivne enhedstyper i vores nyheder corpus
Vi kan se, at mennesker, steder og organisationer er de mest nævnte enheder, men interessant nok har vi også mange andre enheder.
en anden dejlig ner tagger erStanfordNERTagger tilgængelig franltkinterface. Til dette skal du have Java installeret og derefter hente Stanford ner-ressourcerne. Pak dem ud til et sted efter eget valg (jeg brugte E:/stanford i mit system).Stanfords navngivne Enhedsgenkender er baseret på en implementering af lineær kæde betinget tilfældigt felt (CRF) sekvensmodeller. Desværre er denne model kun uddannet på forekomster af PERSON, organisation og placering typer. Følgende kode kan bruges som en standard arbejdsgang, som hjælper os med at udtrække de navngivne enheder ved hjælp af denne tagger og vise de øverste navngivne enheder og deres typer (ekstraktion adskiller sig lidt fra spacy).
Top navngivne enheder og typer fra Stanford NER på vores nyheder corpus
Vi bemærker ganske lignende resultater, dog begrænset til kun tre typer navngivne enheder. Interessant nok ser vi en række nævnt af flere mennesker i forskellige sportsgrene.
Bio: Dipanjan Sarkar er en dataforsker @Intel, en forfatter, en mentor @Springboard, en forfatter og en sports-og sitcommisbruger.
Original. Reposted med tilladelse.
relateret:
- Robust Ord2vec-modeller med Gensim & anvendelse af Ord2vec-funktioner til Maskinlæringsopgaver
- Human Interpretable Machine Learning (Del 1) – behovet og betydningen af Modelfortolkning
- implementering af dyb læringsmetoder og Funktionsteknik til tekstdata: Spring-gram-modellen