KDnuggets
v jakémkoli textovém dokumentu existují konkrétní pojmy, které představují konkrétní entity, které jsou více informativní a mají jedinečný kontext. Tyto entity jsou známé jako pojmenované entity, které konkrétněji odkazují na pojmy, které představují objekty v reálném světě, jako jsou lidé, místa, organizace atd., které jsou často označovány vlastními jmény. Naivním přístupem by mohlo být najít je při pohledu na podstatné fráze v textových dokumentech. Pojmenované entity recognition (NER) , také známý jako subjekt vytržení/extrakce , je populární metoda používá při extrakci informací k identifikaci a segmentu pojmenovaných entit a klasifikovat nebo roztřídit je podle různých předem definovaných tříd.
SpaCy má několik vynikajících schopností pro rozpoznávání pojmenovaných entit. Zkusme to použít na jednom z našich ukázkových novinových článků.

Vizualizace pojmenovaných entit v článku zpravodajství s prostorný
Můžeme jasně vidět, že hlavní pojmenovaných entit byly identifikovány pomocí spacy. Chcete-li podrobněji porozumět tomu, co každá jmenovaná entita znamená, Můžete se podívat do dokumentace nebo se podívat na následující tabulku.
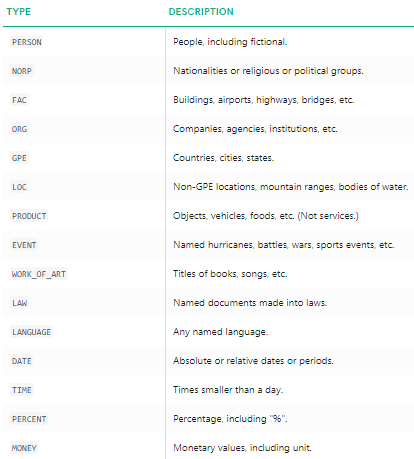
Pojmenované entity typy
Pojďme nyní zjistit nejčastější pojmenovaných entit v našem zpravodajství corpus! Za tímto účelem vytvoříme datový rámec všech pojmenovaných entit a jejich typů pomocí následujícího kódu.
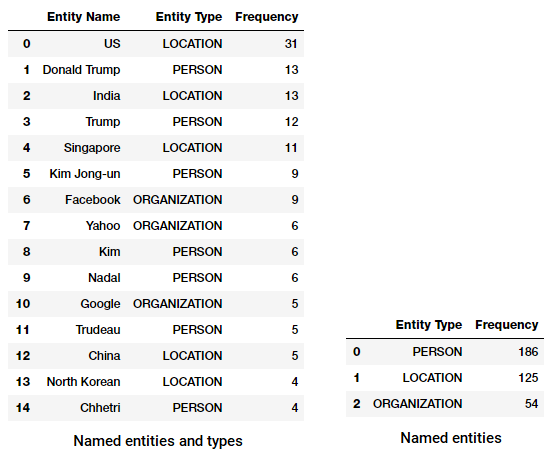
Nyní můžeme transformovat a agregovat tento datový rámec, abychom našli nejvyšší entity a typy.

Top pojmenovaných entit a typů v naší novinky corpus
všiml jste si něčeho zajímavého? (Rada: Možná předpokládaný summit mezi Trumpem a Kim Čong!). Vidíme také, že správně identifikoval „Messenger“ jako produkt (z Facebook).
můžeme také seskupit podle typů entit, abychom získali představu o tom, jaké typy entit se v našem zpravodajském korpusu vyskytují nejvíce.

Top pojmenované entity typů v naší novinky corpus
můžeme vidět, že lidí, míst a organizací jsou nejčastěji uváděny subjekty, ačkoli je zajímavé, máme také mnoho dalších subjektů.
Další pěkný NER tagger je StanfordNERTagger dostupné z nltkrozhraní. K tomu musíte mít nainstalovanou Javu a poté stáhnout zdroje Stanford NER. Rozbalte je na místo podle vašeho výběru (použil jsem E:/stanford v mém systému).
Stanfordův pojmenovaný Rozpoznávač entit je založen na implementaci sekvenčních modelů lineárního řetězce podmíněného náhodného pole (CRF). Tento model je bohužel vyškolen pouze na instancích osob, organizace a typy umístění. Následující kód může být použit jako standardní pracovní postup, který nám pomáhá extrakci pojmenovaných entit pomocí této aplikace a ukázat top pojmenovaných entit a jejich typy (extrakce se mírně liší od spacy).
Top pojmenovaných entit a typů od Stanford NER na naše novinky corpus
všimli Jsme si docela podobné výsledky, i když omezeno na pouze tři druhy pojmenovaných entit. Zajímavé je, že v různých sportech vidíme řadu zmiňovaných lidí.
Bio: Dipanjan Sarkar je datový vědec @Intel, autor, mentor @Springboard, spisovatel a závislý na sportu a sitcomu.
originál. Přeloženo se svolením.
Související:
- Robustní Word2Vec Modely s Gensim & Použití Word2Vec Funkce pro Strojové Učení Úkoly
- lidsky Interpretovatelné Strojového Učení (1. Část) — Potřeba a Význam Modelu Interpretace
- Prováděcí Hluboké Učení, Metody a Funkce Inženýrství pro Textová Data: Skip-gram Modelu